How I Used OpenAI API to improve our product documentation
In this blog post, I share how I used the OpenAI API to improve our product documentation. I used ChatGPT to generate more detailed descriptions for our OpenBB Bot Discord commands, making them more understandable for new users.
The open source code is available here.
The documentation of our free OpenBB Bot was pretty simplistic for most of the commands.
For instance, the description for the command /dp alldp was: "Last 15 Darkpool Trades", as seen below:
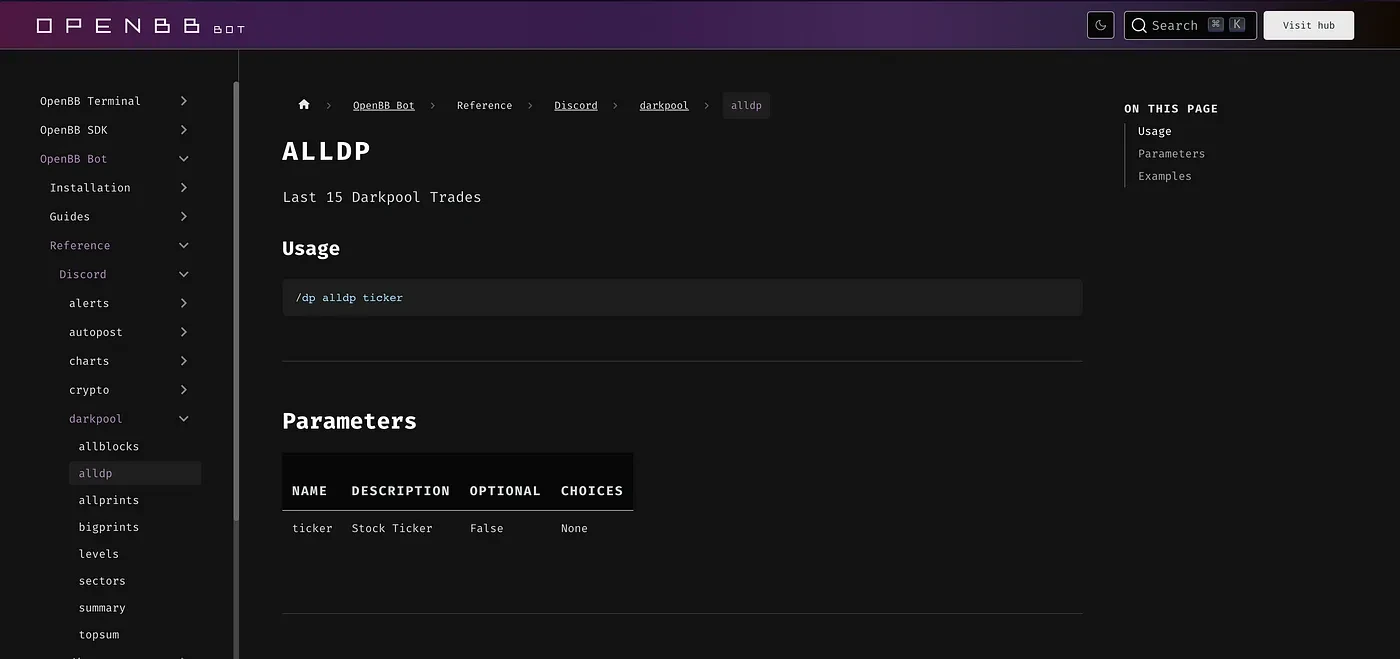
For more experienced traders, this may be enough. But for new users, these 4 words may not mean much.
For context, this is the output that a user would get if running /dp alldp on our Discord server.
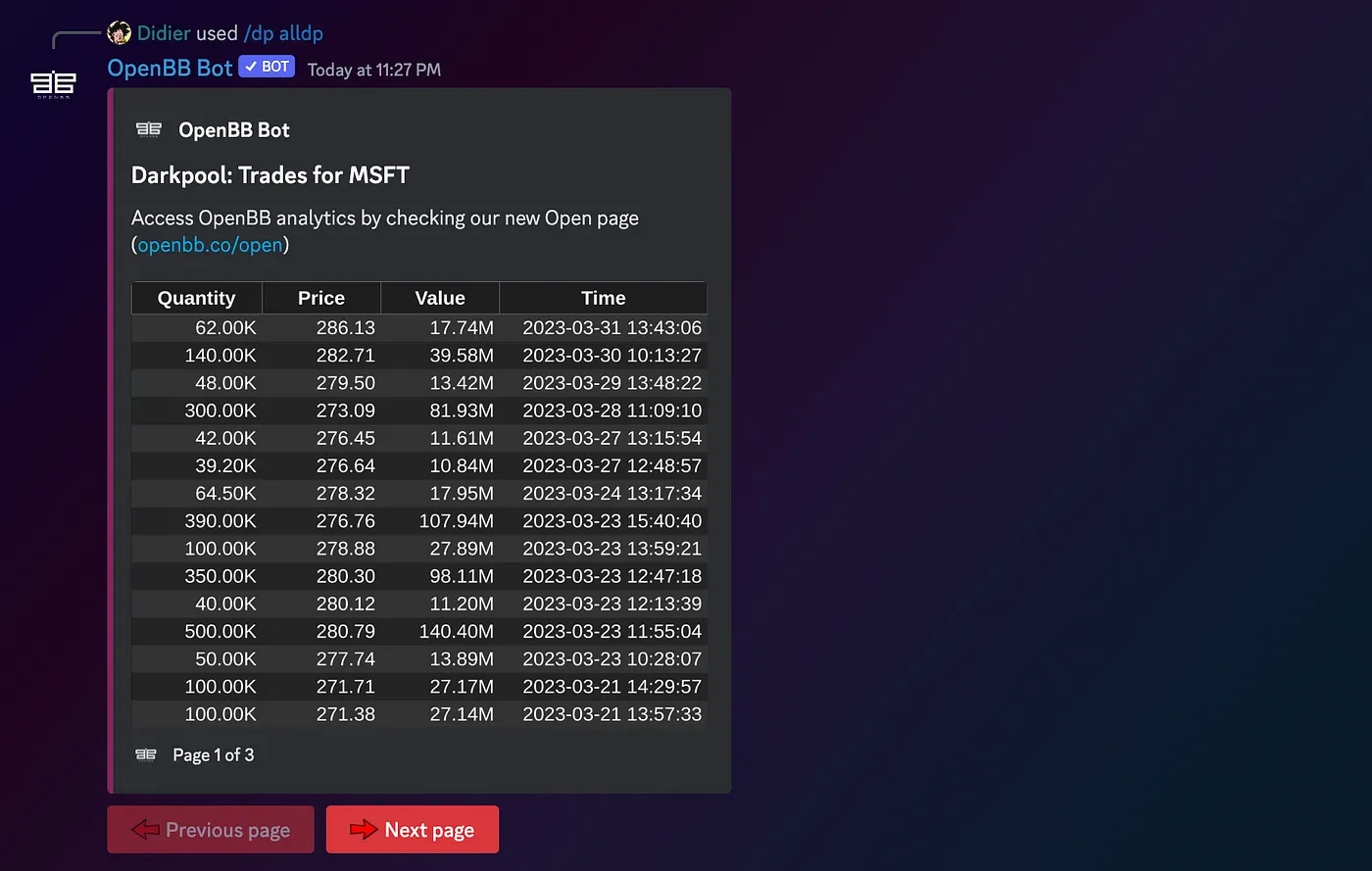
So I talked with someone in our team about improving the documentation. Not only for the new users that wanted to utilize our free product but also so that we could train our own LLM on this better dataset.
Over the weekend I had the idea: What if I provided ChatGPT with the current description and an example of how to use the command and asked it to provide a more detailed description?
So the next step was to try whether ChatGPT would indeed improve the current documentation.
After a bit of prompt tweaking, I got a much better description than the one we currently had. See below:
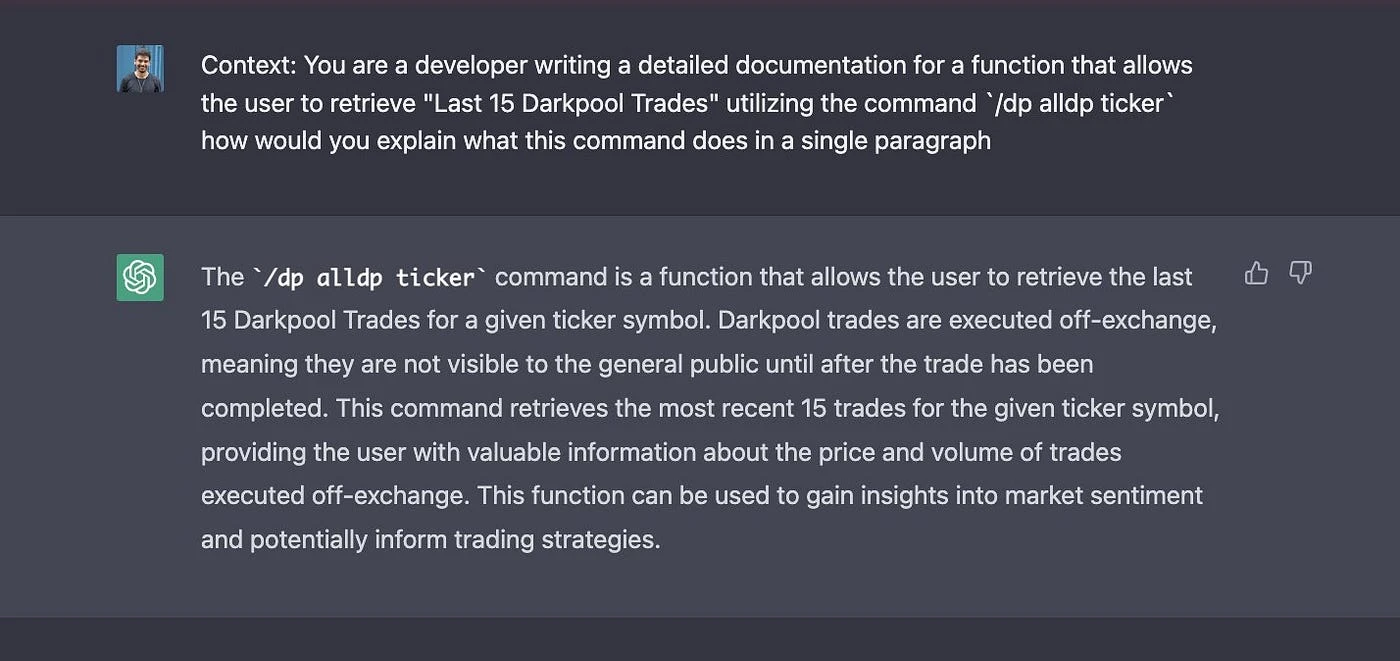
The next step was rather straightforward. I created a script that iterated through all our OpenBB Bot Discord documentation files and updated the old description with a more detailed one.
This is the template prompt that I used:
Context: You are a developer writing a detailed documentation for a function that allows the user to retrieve desc utilizing the command example how would you explain what this command does in a single paragraph”
Where desc and example corresponds to the current description and example that each of our commands have, respectively.
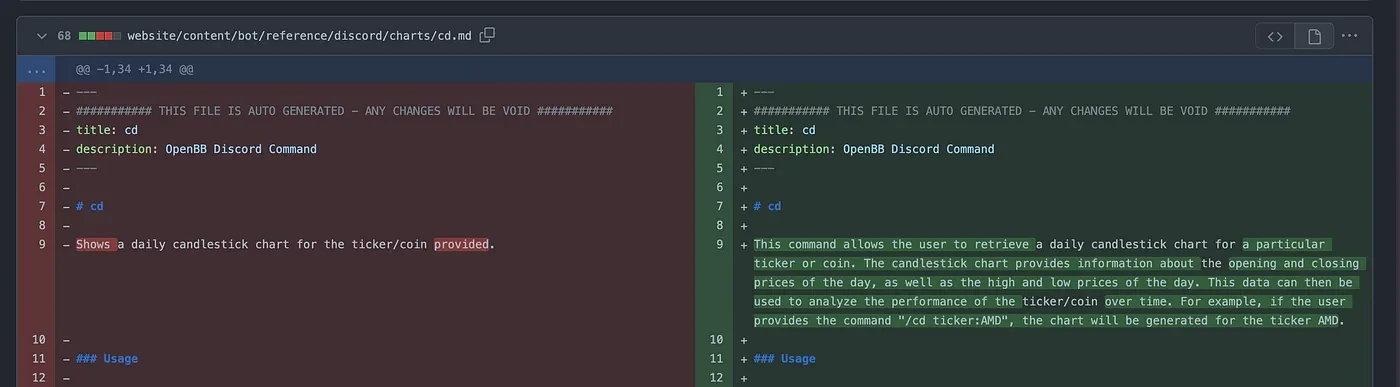
The results can be seen below (done on this PR),
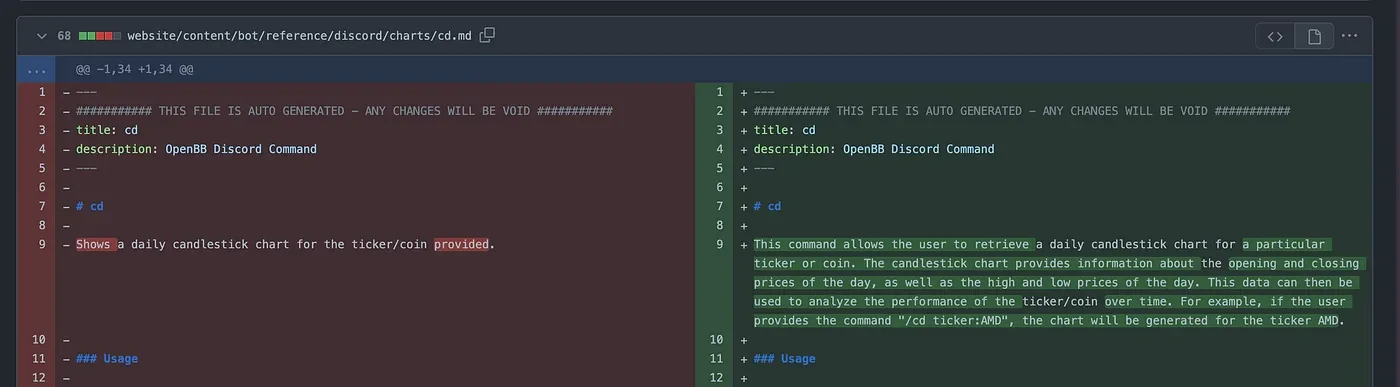
As usual, I open source the script here.
The funny thing is that I used an LLM output to improve our documentation. And we may use this data to train our own LLM.
LLM-ception?