Long-running agents & SLMs embedded in your product
Long running agents as a category will likely be won by the labs and opportunity for startups is to use SLMs around customer use-cases/workflows with all the context they are sitting on.
More than 2 years ago, on January 1st 2024, I published a prediction that fine-tuned SLMs would be on the rise within financial firms. That basically you would need specialized models for different workflows and you would get these by fine-tuning SLMs in your own owned-firm data.
And I did this schema on how we were thinking about this:
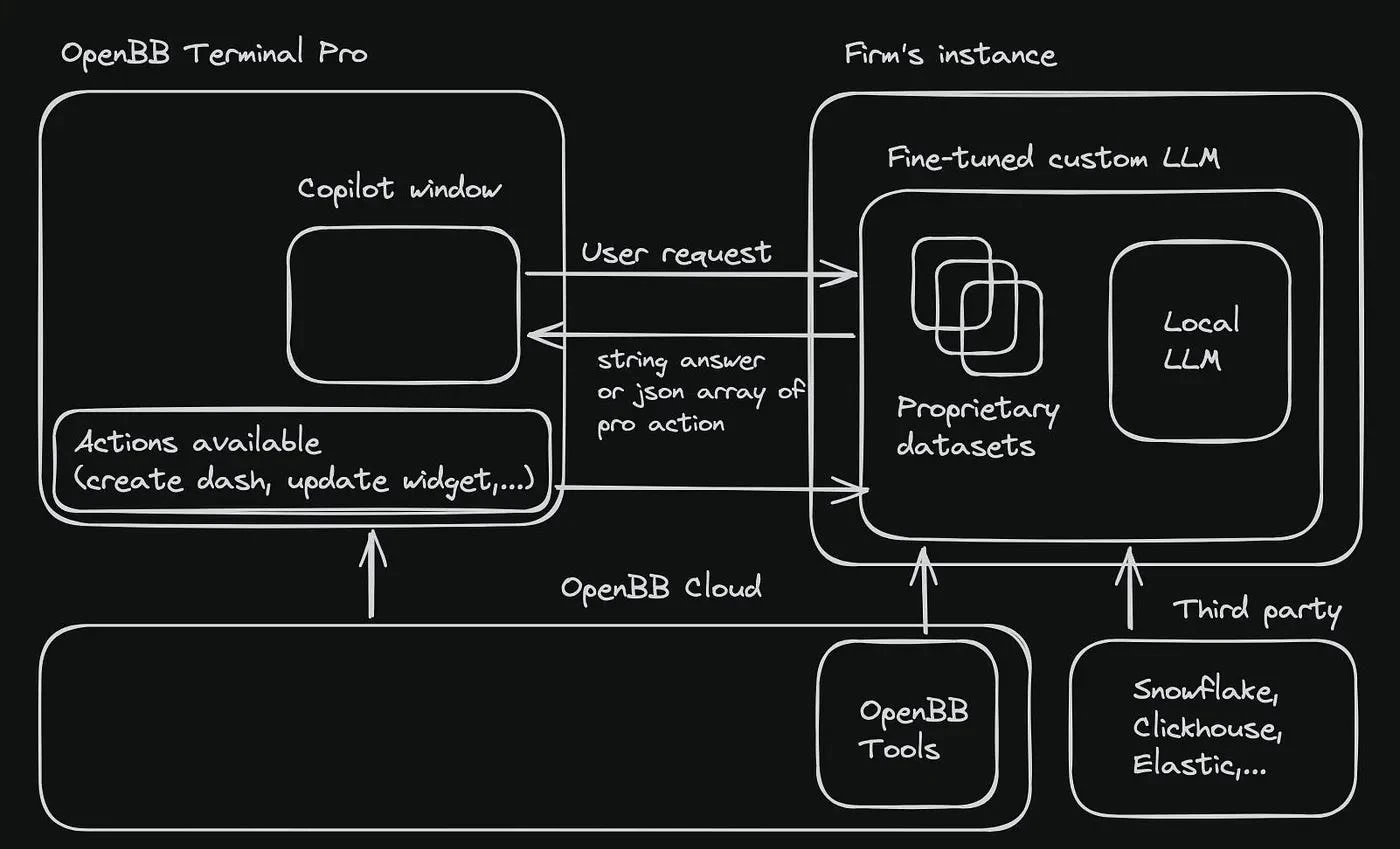
9 months later, I wrote this in another essay titled ChatGPT and the future of AI in Finance:
What a big LLM like GPT-4o is doing is trying to build a single Jarvis that knows about everything. Whereas we could have an SLM that does something extremely well and just focus on that, e.g. translating from English to Portuguese. The benefit of an SLM is that inference is likely faster, can be hosted on devices, and, in theory, it’s better on a topic because it’s been less “contaminated” during training by data that doesn’t relate to the task at hand.
Imagine that a firm decides to use an SLM trained to retrieve data from SEC filings quickly and at scale. Or, we could train our own SLM to understand user intent and interact directly with the OpenBB Terminal interface.
In hindsight, this vision didn’t materialize yet. At least not in 2025 and likely not in 2026, at least not at the scale I was expecting.
But I am still bullish in this category.
In a different way than I was before.
One of the things I didn’t expect was that as the models scaled up, context engineering would make it possible to heavily steer token inference distribution in a way that would have made fine-tuning on a previous model useless.
I mean I expected this to happen for some time, but not for it to still hold almost 2 years later.
In that same post I wrote about this, and even mentioned this sentence that someone at BlackRock said on stage: “it's expensive to spend time fine-tuning a new model, just for that entire work to be 'eradicated' by a new model that has a higher performance in that specific domain than the model has been fine-tuned“
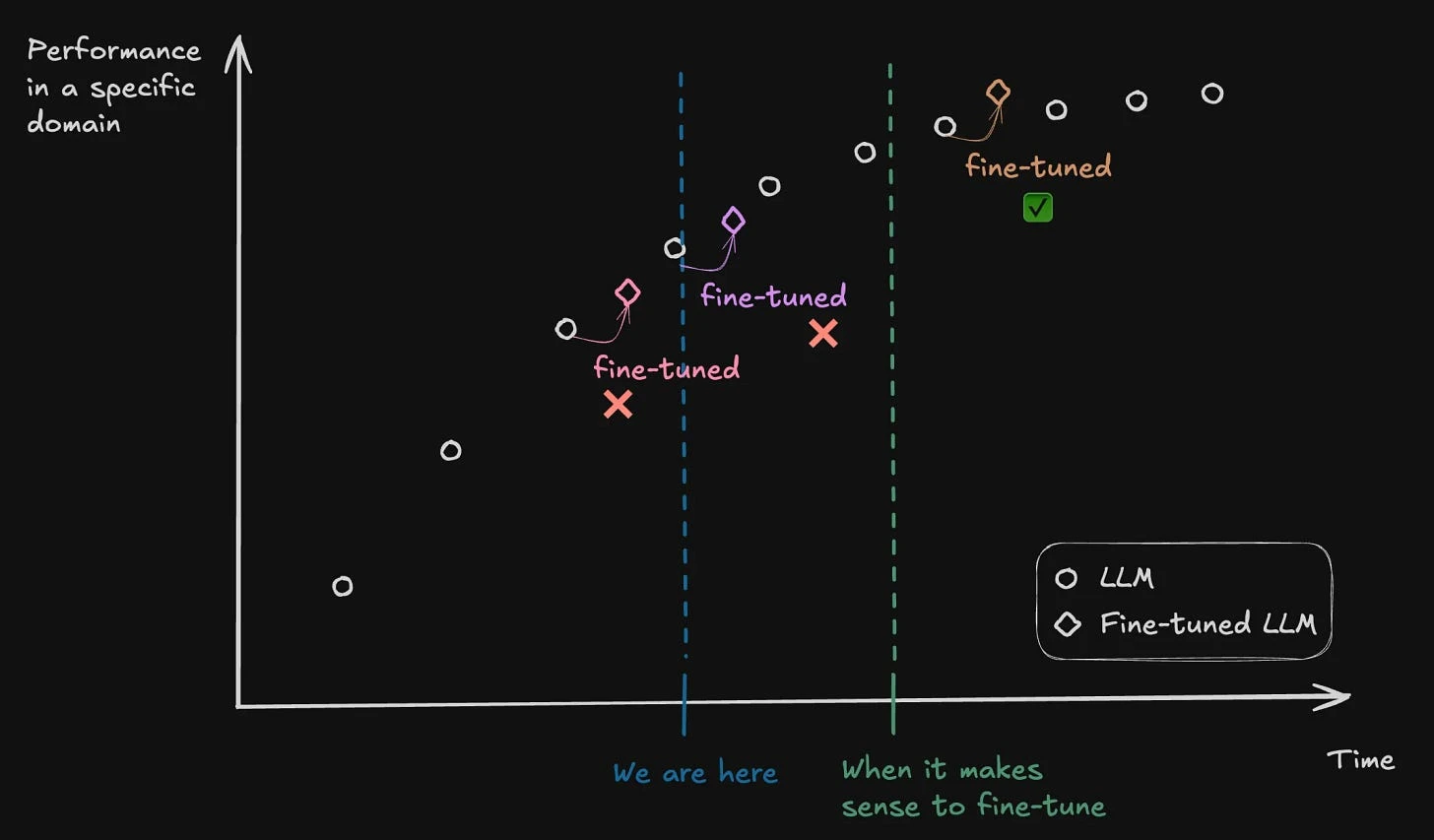
So what is different now? What changed?
People have really pushed what is possible to do with the model. Everyone is using the same models (GPT-5.5, Opus 4.7, …) but the type of workflows are completely different - coding, healthcare, finance, consumer, legal,.. so what differs?
The prompt.
Except that now we don’t call it prompt anymore. We started calling it Context, where you are talking about the system prompt + user prompt + data. But it’s all still the input that the model uses to do forward pass and predict the next token.
And then Context Engineering didn’t encompass enough the amount of engineering around it, and the term “harness” started to pick up.
Harness is pretty much everything surrounding the model weights. How the agent decides to handle internal or external data (structured or unstructured), how it decides to handle past conversation or memory in general, how it decides to ask user for additional questions, how it supports MCP tools and skills, but also additional commands, …
Along with that, an agent having access to its own sandbox with file systems and given more playground started becoming the norm.
Han Lee has an amazing post on the Agent Harness topic, if you want to learn more.
Coding agents won because they had the perfect environment to thrive. And it turns out that many domains can be boiled down to a coding agent + well defined context and workflow.
Now the thing that I didn’t expect was that the labs would go as vertical as they have. It doesn’t shock me given that’s where value ($$$) lies - but it still caught me off guard as they alienated startups being built on top of their models. Many of them.
The prize was just too high for them to not do it.
Not only that, but they understood that context is king and the more data they can get their hands on (particularly as they’ve already exhausted most available data out there) the more powerful their models become.
So if you understand that, what is your next move?
It’s to have people do work on your products so that net new data gets to be used. But they are not just training on normal user data. No. They are training on user data along with their interactions with their product.
At this point the harness is becoming part of the training set. So you are going to go very uphill if you are trying to beat Claude Code by utilizing Opus 4.7 in a different harness, or trying to beat Codex using GPT-5.5 in a different harness. Ultimately, I think Cursor has realized this - hence the buy-out option of xAI making total sense.
And due to the nature of coding agents and how “general” they can be because everything is code - I think labs will win the long running / autonomous agents. If you need proof points on this, track what the labs are sharing on their blogs (this is one of the best ways to understand their priorities):
Even well capitalized startups, such as Cognition and Cursor (2.5bn and 3.3bn raised, respectively) are talking about the challenges around scaling cloud / autonomous agents.
-
“Building cloud agent infrastructure requires two investments: the technical infrastructure to run agents securely and autonomously in the cloud, and the change management to make agents productive across your engineering org. We've spent over two years on both, for Devin. What follows is what we've learned.” - https://cognition.ai/blog/what-we-learned-building-cloud-agents
-
“During that experiment, we saw frontier models fail in predictable ways on long-horizon tasks. We addressed these limitations by creating a custom harness that enables agents to take on more difficult work and see it through to completion.” - https://cursor.com/blog/long-running-agents
And so as a startup, your best best is to create the tools that these agents crave to do workflows in your specialized domain.
For us, that is the Workspace MCP. Where Codex/CC can access the Workspace data, based on the right data entitlements and roles.
Codex controlling my Open Portfolio dashboard via Workspace MCP
Codex creating a slide deck from the Open Portfolio via Workspace MCP
But can also create widgets, dashboards and apps for the Workspace.
Codex one-shot a Kalshi App for the Workspace via Workspace MCP
So where do small models still win?
Back to my original bet.
I said I’m still bullish in this category, just in a different way. Here’s what I mean.
The frontier models will (have?) win the long, autonomous, general-purpose layer.
But there’s another opportunity - the small/fast agentic experience within a product, where a model has to do a specific job, at a specific volume, under constraints the frontier model can’t satisfy.
Three reasons for such small embedded models.
Cheaper.
The clearest example is Cursor’s tab model. It runs every time you type. If Cursor was calling Opus 4.7 (or 4.8 by the time this is live lol) for every autocomplete suggestion, the unit economics of a $20/mo product wouldn’t work. So they trained a small model on their own data and now it runs constantly at a fraction of the cost. Tools like Tinker are making this viable for more application companies.
Faster.
SLMs are small. Small means fast.
Frontier models will keep getting faster, but they’re built for long reasoning, not for tight inference loops inside a UX flow. For an autocomplete that runs while you type, a classification step inside an agent loop, a widget that re-scores as data changes - you need a response in milliseconds, not seconds.
Secure.
This is the strongest reason for OpenBB’s clients.
Hedge funds, asset managers, family offices, banks - they have data residency and air-gap requirements that make frontier API calls structurally impossible for certain workflows. You can’t ship sensitive client data to a third-party endpoint. An embedded model that runs wherever the product runs in your own environment is the only way tou can stay within compliance requirements.
Here’s our take on this:
This is a preview of a new agent we have coming where I am building a CME dashboard using an open weight GLM-5.1 that we could tweak to optimize for this type of workflows; and then I work on that dashboard with GPT-OSS 20b which is running locally on my machine (Macbook Pro M3 48gb).
In the end when the artifact is created you can see that the name of the widget and metadata are automatically created by this SLM, to show that this small model focuses on the end user experience.
Where are we heading
I don’t think startups should try to beat the labs at autonomous agents. Labs have the compute, the data, the harness, and now the context of these long running flows. A lot of these actually happened because of the adoption of MCP universally, where there was no friction from users to use another product as they could connect data to their favorite agent.
Data incumbents in particular should, imo, try to hold their data + context to try to win the workspace infrastructure where work happens. Make labs come to them, not the other way around. Almost like an MCP for agents rather than an MCP for data and tools.
Given the state of the world, I would build the tools long-running agents crave inside your domain. Expose your product through MCP. Make it easy for Codex, Claude Code, and whatever comes next to do real work inside your runtime. For us, that’s the Workspace MCP.
Inside your product, ship small models for the workflows that need them. Tight latency loops. On-prem deployments. Anything that needs to be tuned against your specific data or run on the client’s hardware.
Treat both as complementary. The long-running agent and the embedded model are doing fundamentally different jobs.