My first-hand experience on AI impacting education through Perplexity, Cursor and ChatGPT
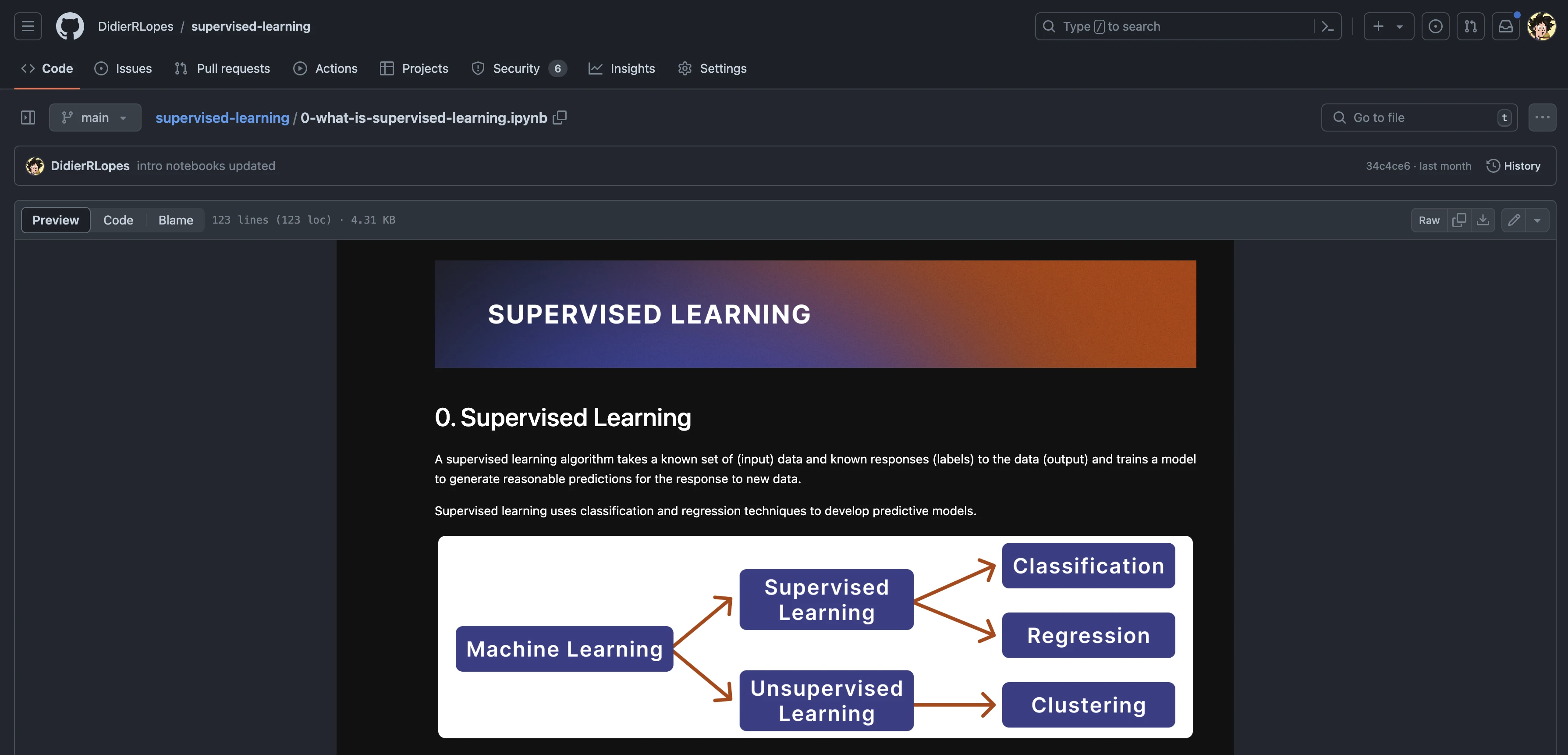
AI will change education forever. Here's how I leveraged Perplexity, Cursor and ChatGPT to teach Supervised Learning and assess coursework.
The open source code is available here.
Recently I was invited to teach a course in Big Data and Data Analytics at Europeia University. I gave 4 hours of classes, divided into:
- Supervised Learning - Theory
- Supervised Learning - Practice
And then evaluated the students coursework.
Creating a new syllabus
My past experience as a teacher happened during my BSc., back in 2016, where I was a TA for the course of Signal Theory and had to help students in their coursework through Matlab/Octave.
Things were different at the time because I had a syllabus to follow and most of my time was spent helping students if they were blocked coding-wise or had some questions regarding the theory.
And of course - there was no AI. At least not in the sense that we speak about today - i.e. there were no LLMs.
This time was different - I had the flexibility to choose what I was going to cover about Supervised Learning.
I've never worked as a Data Scientist per se, but have been passionate about data for a while and spent a lot of time reading books and learning about the topic. In my previous company, I started playing with IMU data in my spare time which lead me to publish a paper at ICMLA where I used Support Vector Machine (SVM) for Step Detection using Nurvv trackers and even open sourced the code here.
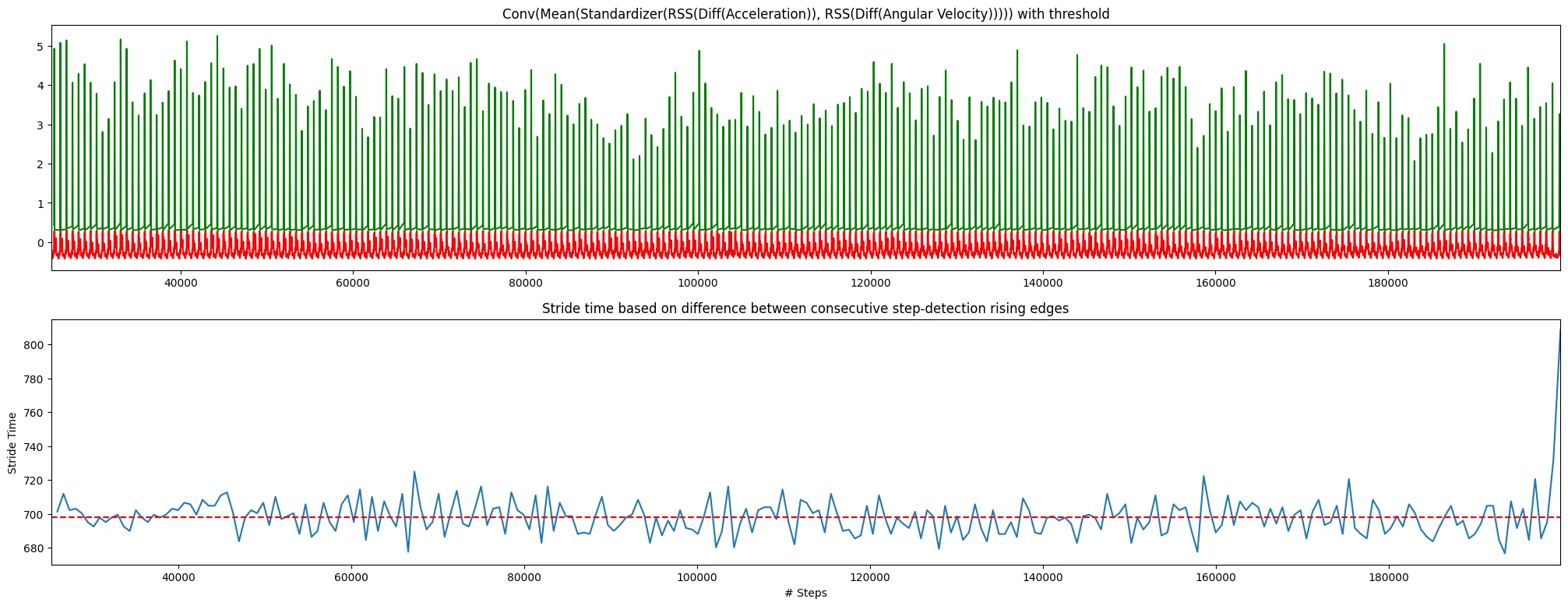
I've wrote about this and how I managed to write the entire code in my spare time in a single week, and missing the yearly team event in order to pull this off. You can read more about it here.
But so the question is:
"Where do I start?"
My first intuition was to gather some of my favorite books and courses on the topic and understand how they presented the overall subject. I wouldn't have the same time, so I would need to touch on most topics briefly - enough for students to know about it and explore further if curious.
However, given my time constraints with running OpenBB, I would have had a hard time since I would need to:
- Consume the content of these books and courses
- Mix and match them
- Cut to fit the time constraints
- Produce a final syllabus that I'm confident about
This was not a trivial task, and definitely not a weekend job.
Except that IT WAS.
Perplexity enters the chat
Since Perplexity's main value proposition is being better at Google than Google - I popped the following prompt into it.
BAM.💥
This was exactly what I was looking for.
Did it give me the content end-to-end that I was expecting?
No.
Was it a perfect starting point?
Yes.
I didn't literally copy-paste it. I took the parts I liked, re-iterated on the ones I didn't until I eventually did. Plus, use my experience to prioritize parts that I felt should be more relevant vs others.
Were there some hallucinations?
Yes, it's not a silver bullet.
But it saved me DAYS of work.
I was dreading having to write the syllabus and like this, it was actually fun. It was fun because I felt like Perplexity was acting as my assistant and I was engaging in a conversation of what should be contained within the course and what shouldn't.
After having all the content ready, I asked my wife to help me with some images to make it easier for students to understand concepts.
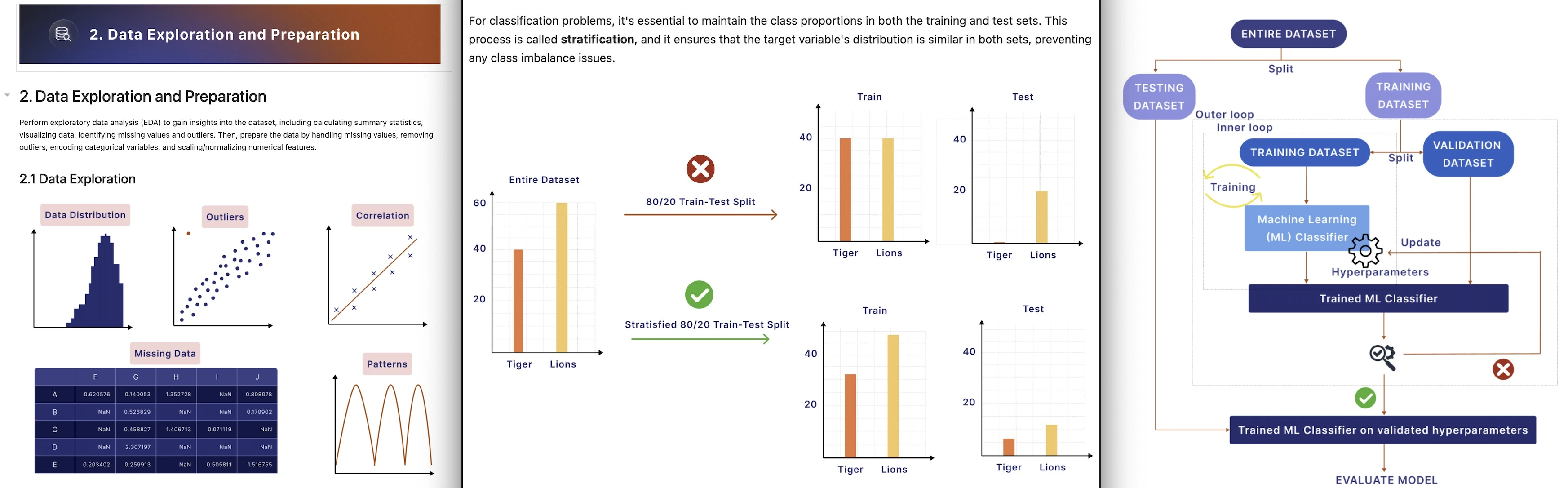
I was happy with the results - but wanted a second opinion. So I asked a friend of mine who's been a DS for over 6 years what his thoughts were on the materials I worked on - and he was impressed about the speed.
Being a fan of open source, I have open sourced all the theory and practice of the course and you can access it here: https://github.com/DidierRLopes/supervised-learning
For the practice exercises I made it so that users can run it with colab directly on the browser to focus on the learning and not on the installation of libraries - highly recommend doing this.
Assessing students grades
After presenting the classes to the students, they had to work on a final project that involved supervised learning - and I had to grade their work on it. The grade was from 0 to 5 and I was given freedom in terms of what criteria to use.
So I did what someone else in my shoes would do.
ChatGPT to define grading criteria
I typed chat.openai.com and had a conversation with ChatGPT about the best way to grade the coursework. I wanted it to be as fair as possible, but also evaluate students based on criteria outside of coding, such as problem formulation and documentation/clarity.
Note: Story for another day but with the raise of LLMs, I have a very strong opinion that documentation and clarity will be as important as the code itself.
This is the outcome of that conversation:
PART I - Problem Formulation
1.a. Clarity and Definition: Is the problem clearly defined and well-formulated? Are the project's objectives explicitly mentioned?
1.b. Relevance and Context: Is the relevance of the problem within the application domain explained? Does the problem justify the use of supervised learning?
PART II - Documentation and Quality
2.a. Code Quality and Readability: Clarity and Structure: Is the code well-organized with clear and consistent formatting? Are comments used effectively to explain complex logic? Best Practices: Does the code follow standard coding practices (e.g., naming conventions, modularization)? Are functions and classes used appropriately?
2.b. Documentation and Explanation in Comments or Notebook Markdown: Clarity: Are the results and methodology clearly documented? Is there a detailed explanation of the steps taken and the reasons behind them? Visualization: Are visual aids (e.g., graphs, plots) used to illustrate key points and results? Are these visualizations clear and informative?
PART III - Code
3.a. Data Preprocessing and Cleaning: Completeness: Are all necessary steps for data preprocessing included (e.g., handling missing values, encoding categorical variables, scaling features)? Justification: Are the preprocessing steps justified and explained? Is there a clear reason for the choices made?
3.b. Data Exploration: Initial Analysis: Is there an exploratory data analysis? Are descriptive statistics used to better understand the data? Visualization: Are visualizations (e.g., graphs, plots) used to illustrate data distribution, correlations, and important patterns? Are these visualizations clear and informative?
3.c. Model Implementation and Training: Correctness: Is the model implemented correctly according to the chosen algorithm? Are appropriate libraries and functions used? Parameter Tuning: Is there evidence of parameter tuning or optimization? Are the chosen parameters explained and justified?
3.d. Evaluation and Validation: Metrics: Are appropriate evaluation metrics chosen and calculated? Are these metrics relevant to the problem at hand? Validation Techniques: Are appropriate validation techniques used (e.g., cross-validation, train-test split)? Is there an analysis of the model's performance on both training and testing data?
This was it.
Exactly what I was looking for.
Now I could grade a student on each of these criteria, then select a final grade weight for each criteria (e.g. 5-15%), create a spreadsheet with such a table and call it a day.
However, the most time-consuming task was coming - the grading itself.
There were 10 groups in total. So 10 notebooks that I had to look into, exploring completely different datasets with a different ML model being used, different ways to do exploratory data analysis, different ways to assess the model, different objectives, …
Cursor helping with grading
I opened cursor (which is basically VSCode + ChatGPT) and probably the software I've recommended the most to developers in 2024.
And opened my first notebook.
Then I thought, what if I had GPT-4o on my side - helping me to assess this coursework.
It didn't need to be perfect because I was doing it myself, but it could help me understand if there was any critical thing that I missed OR if it completely had a different grade than the one I was going to provide - which would enable me to spend more time on that criteria and iterate.
It gave me confidence that I was being fair to the students.
And made me realize how hard it is for professors when they have 100s of students and have a subjective answer to grade. It's impossible to get it right. They try their best, but as soon as the answer is not binary (0 or 1), they are doomed to fail.
So how did I do it?
Given that I just wanted GPT-4o to quickly review each of the criterias based on the code, I created a prompt that I could use for all of notebooks that the students sent.
This is what my setup looked like
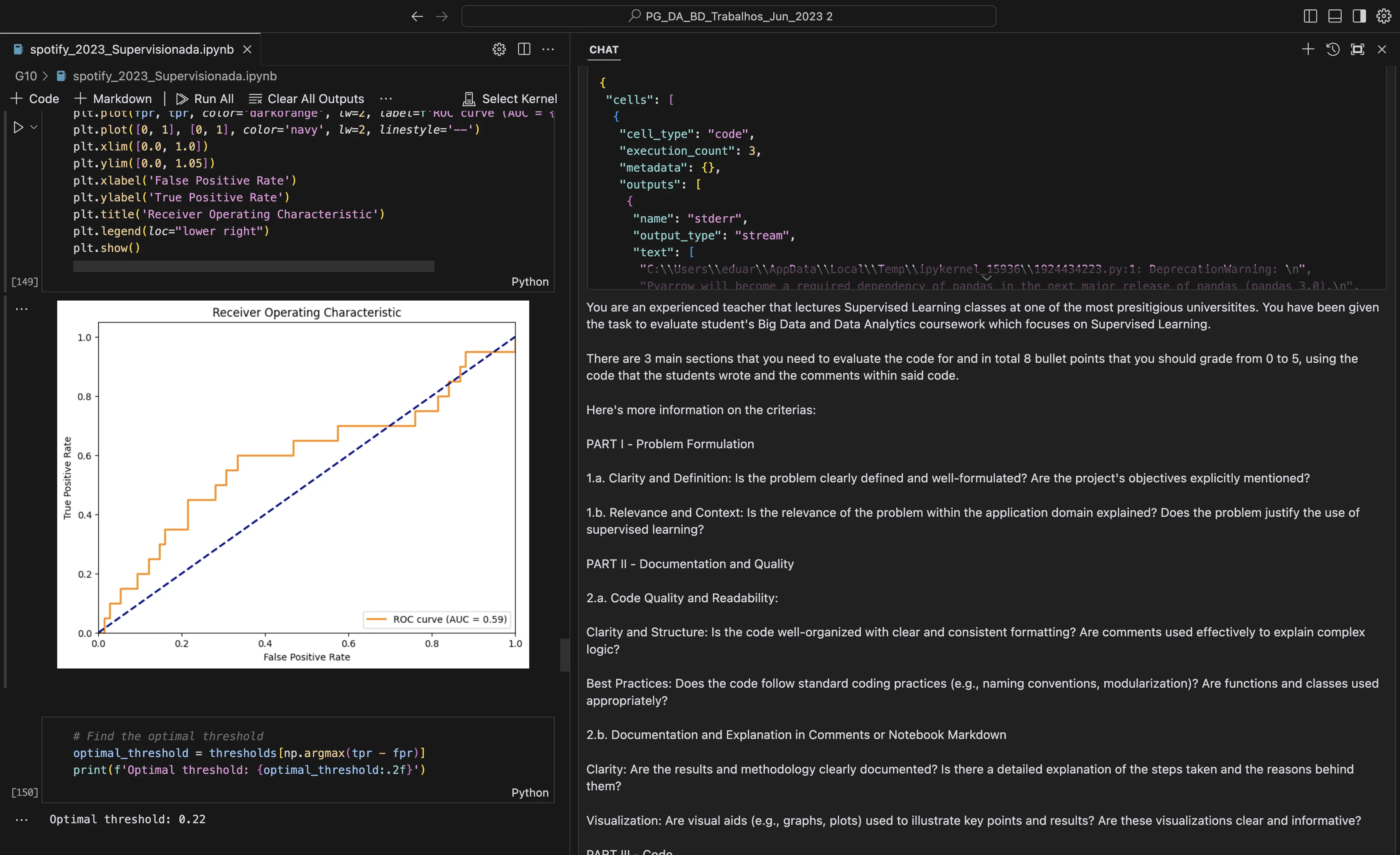
Having the code on the left side and the copilot on the right side that I could use to chat really enabled me to grade more confidently.
Here's an example of a section of a response I got to one of the student's notebooks
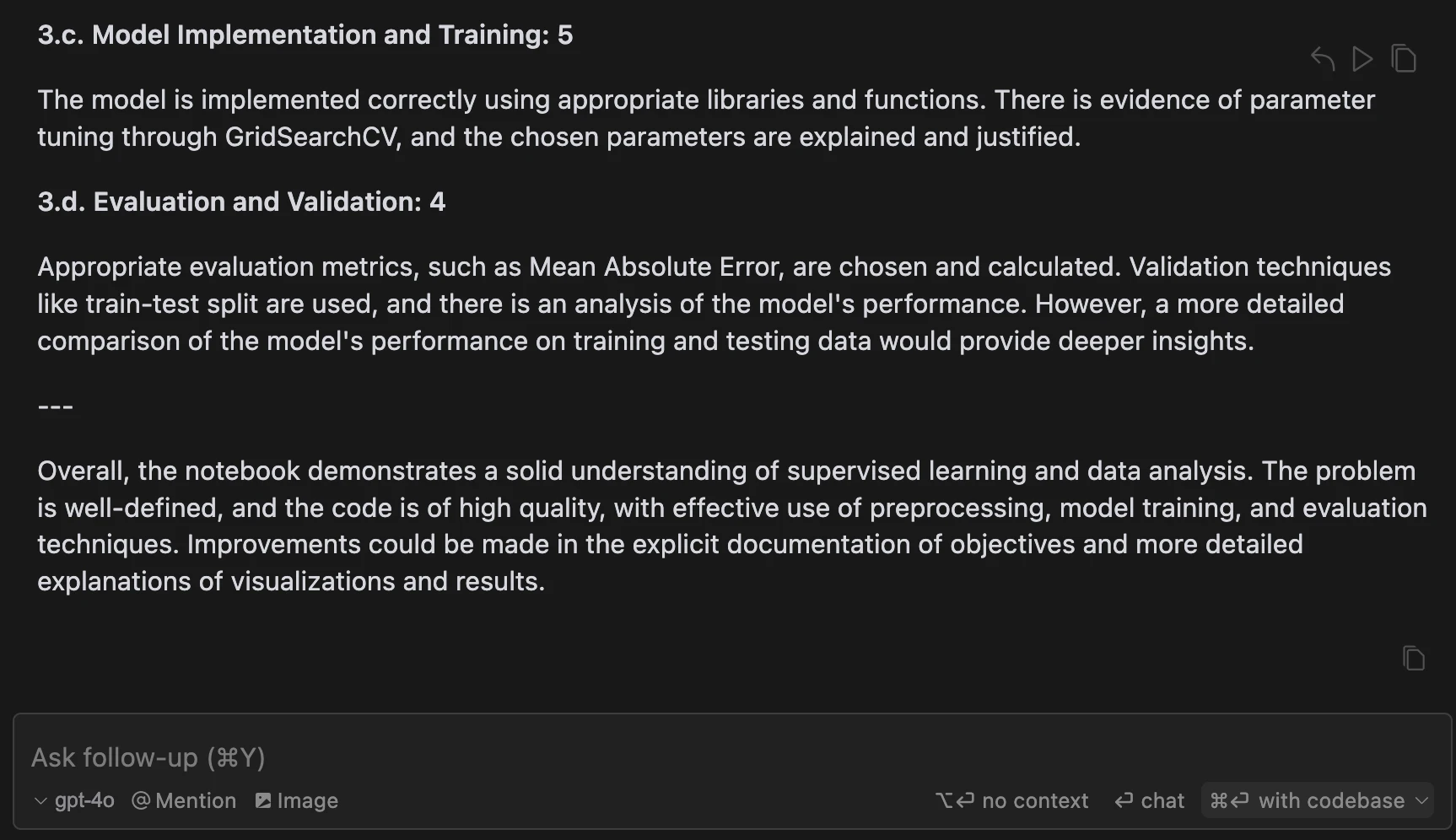
One thing I did to have the copilot produce better outputs was to push it to do chain-of-thought (CoT). Meaning that I prompted the model to explain the reasoning behind a decision before providing a grade. This has been proved to yield to less hallucinations and more accurate responses - which is what I was looking for.
What if I wanted to do this at scale?
I would have put more effort into the prompt and focused on evaluating 1 criteria at a time. I would have done few-shot prompting where I put examples of what grades 1,2,3,4,5 look like for such criteria so the model has those references and can check for similarity of issues committed or successful tasks performed.
Note: the model was able to interpret comments written in Portuguese which is another benefit.
Democratizing access to tutors
While I was working on my prompts to get some feedback from AI in terms of student's coursework I realized that I only need $20/mo to access them.
But then I realized - so do the students.
This means that the students have no reason to NOT run their entire coursework by a LLM that can act as a critic of their work.
They can keep iterating until the model doesn't find anything - hence making students feel more confident about the work they are putting forward.
My initial thought was: "this feels like cheating" (right after the - "I wish I had this a few years ago").
But it actually isn't.
Tutors have existed for a long time.
Students pay tutors to spend time with them to learn outside of classes - whether it's explaining the theory or helping with coursework.
However, tutors are a vitamin and not a painkiller (they are a nice-to-have and not a must-have). And because they aren't a requirement, it's not a typical choice among lower-income families.
On the other hand, kids from wealthy families often have multiple tutors. Not for students who are almost failing their class, but who want to bump their grades from A- to an A+.
But this is about to change.
For the most part, GPT-3.5 is accessible for free.
This means that everyone can have access to a tutor that they can work with to have better grades but also produce better coursework.
This means that the concept of a tutor will be democratized and the playing field between students who come from different wealth backgrounds will be leveled and fair.
A final thought on open source
Another class that I had to give to students was "Data Analytics in Financial Markets".
The goal here was to have a more real-life application of data analytics, particularly in financial markets - and even feature OpenBB which has partnered with this university.
But when I started working on the content from scratch, I wondered.
Can't I find a repository on GitHub that suits my needs?
And I did.
The GitHub repository I found was the GitHub repository that contains the code for the case studies in the O'Reilly book "Machine Learning and Data Science Blueprints for Finance" written by my friend Hariom Tatsat: https://github.com/tatsath/fin-ml.
So why would I spend the time re-inventing the wheel when I could just walk students through a few of these case studies?
This is what I did.
Which then made me think that all of this data has been already fed into foundational models, and so even if I were to apply the same approach I did earlier with Perplexity or ChatGPT - it is likely that with a good prompt some of the main examples would have been derived from this repository.
But in this case, this repository already had the perfect case-study format I was looking for, and so I can more easily credit the author.
which made me wonder:
How will open source authors be able to get credit for their work when all of it is being translated into weights in a big neural network architecture?