Creating an AI-powered financial analyst

Our Platform aims to empower the OpenBB Copilot, an AI-powered financial analyst, to perform tasks ranging from knowledge retrieval to fully autonomous analysis. The architecture involves task decomposition, tool retrieval, and subtask agents, showcasing impressive results in both deterministic and non-deterministic workflows. Read on to explore its capabilities and don't forget to watch the demos.
The open source code is available here.
Introduction
At OpenBB, we have been thinking deeply about how AI will impact the lives of analysts and quants. We recently announced the OpenBB Platform and have refactored it from the ground up to make it easier and simpler for quants/developers to access financial data. In addition, we hired a new head of AI to lead our AI efforts - you can read more about it here.
I did a 20-minute presentation at the Open Core Summit on this topic that you can watch here:
Otherwise, the following post will summarize what we presented.
AI-Powered financial analyst roadmap
When discussing what tasks we wanted our AI-powered Financial Analyst to be able to perform, we arrived at the following levels (in order of complexity):
-
Knowledge retrieval: The agent can answer general financial queries without external resources. (eg. ChatGPT "as-is"). Here, the agent relies solely on its training data to answer questions.
-
Data retrieval: The agent can answer queries using information inserted into the context (usually as part of a separate data retrieval process that isn't controlled by the model, such as using similarity search across a knowledge database using the user's query).
-
Autonomous data retrieval: The agent can answer queries by dynamically retrieving data not currently present in the context or the training data via function calling.
-
Complex workflow execution: The agent can reason and answer queries that require a logical arrangement of knowledge retrieval, data retrieval, and autonomous data retrieval calling. It includes action planning and decision-making.
-
Fully autonomous analyst: The agent can do all of the above but is self-directed. The agent can dynamically generate additional hypotheses, modify plans of action, and retrieve the necessary data, all while mid-workflow. The agent can make arguments for certain decisions, carry a discussion on the topic, and reason with you.
Our goal is to enable OpenBB Copilot to perform all of the above. I presented a demo of how it would work in this video:
Two types of prompts
Rather than first building an AI-powered financial analyst for the sake of it, we instead started from what we wanted to achieve. We came up with two distinct prompts and our goal was for the agent to be able to successfully perform both of these, but utilizing the same underlying "agentic" architecture.

-
Prompt A (on the left) - requires linear reasoning (where future answers depend on previous answers). This kind of prompt is generally deterministic, which allows us to access (and verify) the agent's answers immediately because we can check the underlying facts and data. It also involves a few complex operations across multiple steps, such as extracting a list of tickers from an endpoint and iterating through that list using a different endpoint. Then based on those outputs, a reasoning can be made and a final answer is given.
-
Prompt B (on the right) - requires independent reasoning (fetching and combining different pieces of independent information). This prompt is typically less deterministic and allows us to leverage LLMs to provide alpha by uncovering insights that would be hard for a human to discover (or, at the very least, discover at scale). Instead of telling the agent what to do explicitly, we instead pose a question and expect the agent to execute an analysis and perform reasoning, without specific guidance or guardrails.
OpenBB Platform
Getting started with our Platform is extremely easy (docs here). All you need is pip install openbb and you are ready to access 100+ different datasets.
We standardize the data so that you can read our docs once and interact with the Platform the same way, regardless of the type of data you are looking at.
In addition, using the OpenBB Hub, you can set up your API keys which we can manage on your behalf, and all you need to access data via OpenBB is a Personal Access Token.
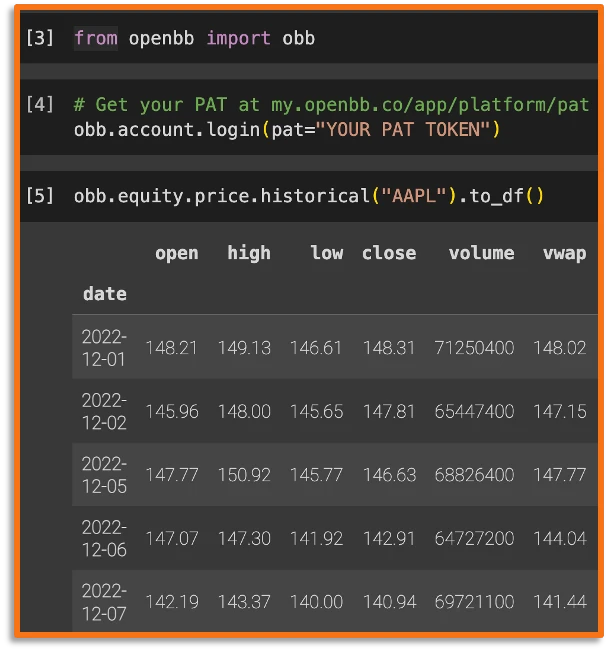
Crucially, we use Pydantic for all of our endpoints. This ensures that we have both structured inputs and structured outputs. This is extremely important as we feed these models into our agent so that it understands both the input schema during function calling, but also the output schema of the resulting function call. This is standardized across multiple data vendors across the OpenBB Platform.
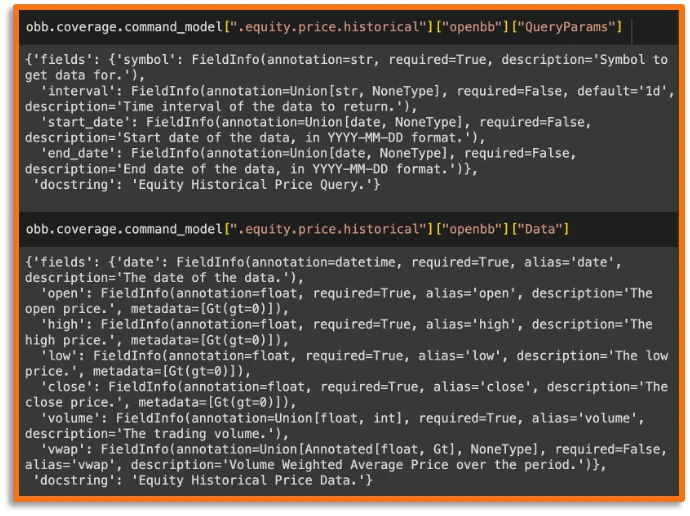
OpenBB Tools
From having 100+ different data endpoints that you can access using Python, we created "tools" that an agent "understands" and can use. This is extremely important since this collection of tools will give real-time data to the agent based on the prompt asked.

Since the OpenBB Platform has high-quality documentation, we use each function's docstring as well as the output field names (with some basic preprocessing). This tweak allows the agent to know where to get the market cap information from, even if it's within a differently-named endpoint (for example the equity.fundamentals.overview endpoint).
Each of these tool descriptions is converted into embeddings that can be retrieved later on based on the query the user provides. This allows our agent to pick the right tools for the job - i.e. if I want to have access to Apple's market cap, I want to get the tool equity.fundamentals.overview because I know that by providing the symbol AAPL I can get the market cap value.
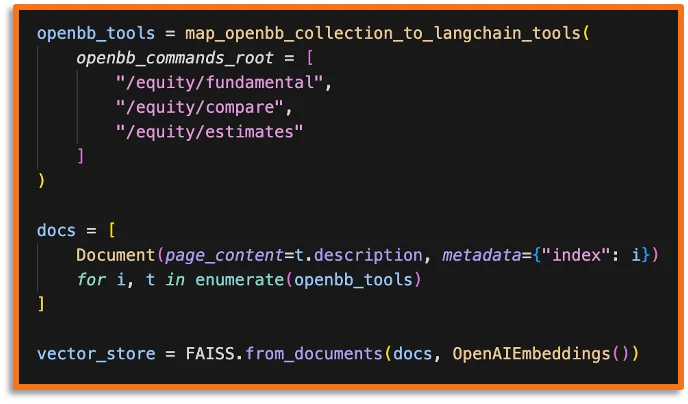
So, we create a vector store using FAISS (Facebook AI Similarity Search) and OpenAIEmbeddings, although any vector store with similarity search would also work.
OpenBB Agent Architecture
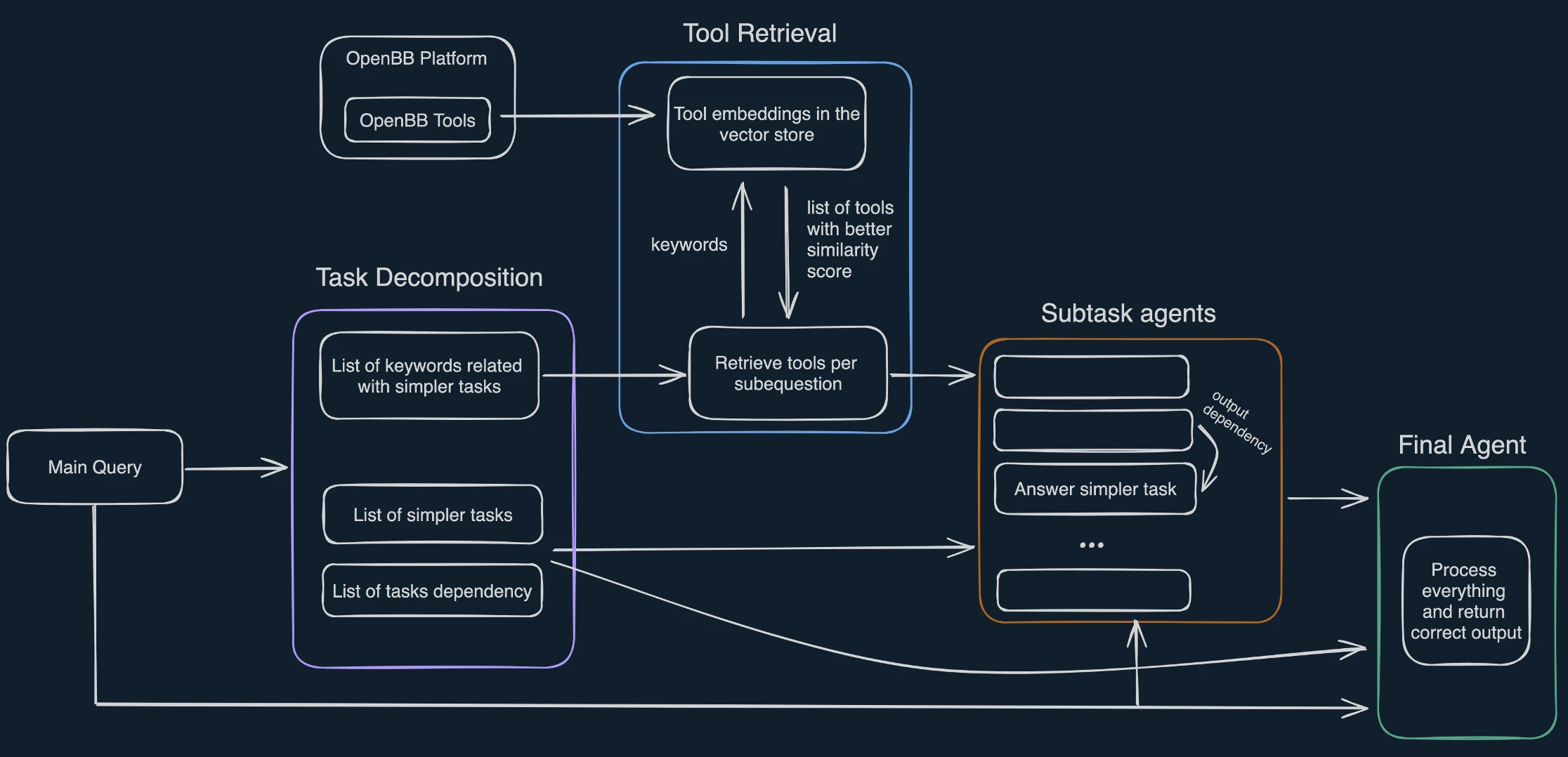
This is the overall architecture that our agent will follow, and below we will talk about each of these components individually.
Task Decomposition
First of all, we don't want to tackle the user query in one go. This is because LLMs have limited context. Plus, we want the agent to retrieve all the necessary tools to answer the query. But the vector's store similarity search doesn't work with one prompt that needs multiple different tools. Additionally, similar to human analysts, breaking a larger question up into smaller manageable subquestions leads to better analysis and results.
So, we break the user's main query into:
-
List of simpler tasks: self-explanatory
-
List of tasks dependency: does the current subtask need a prior subtask to tackle the current subtask?
-
List of "tool search" keywords associated with each subtask: instead of using the subtask question itself to directly retrieve the correct selection of tools using the embeddings in the vector store, empirically we found that if the LLM could select the most important keywords associated with the task using keyword search. This ended up resulting in a big jump in retrieval performance. This is expected since we are effectively reducing the noise. E.g. "What are Tesla peers" → "peers".
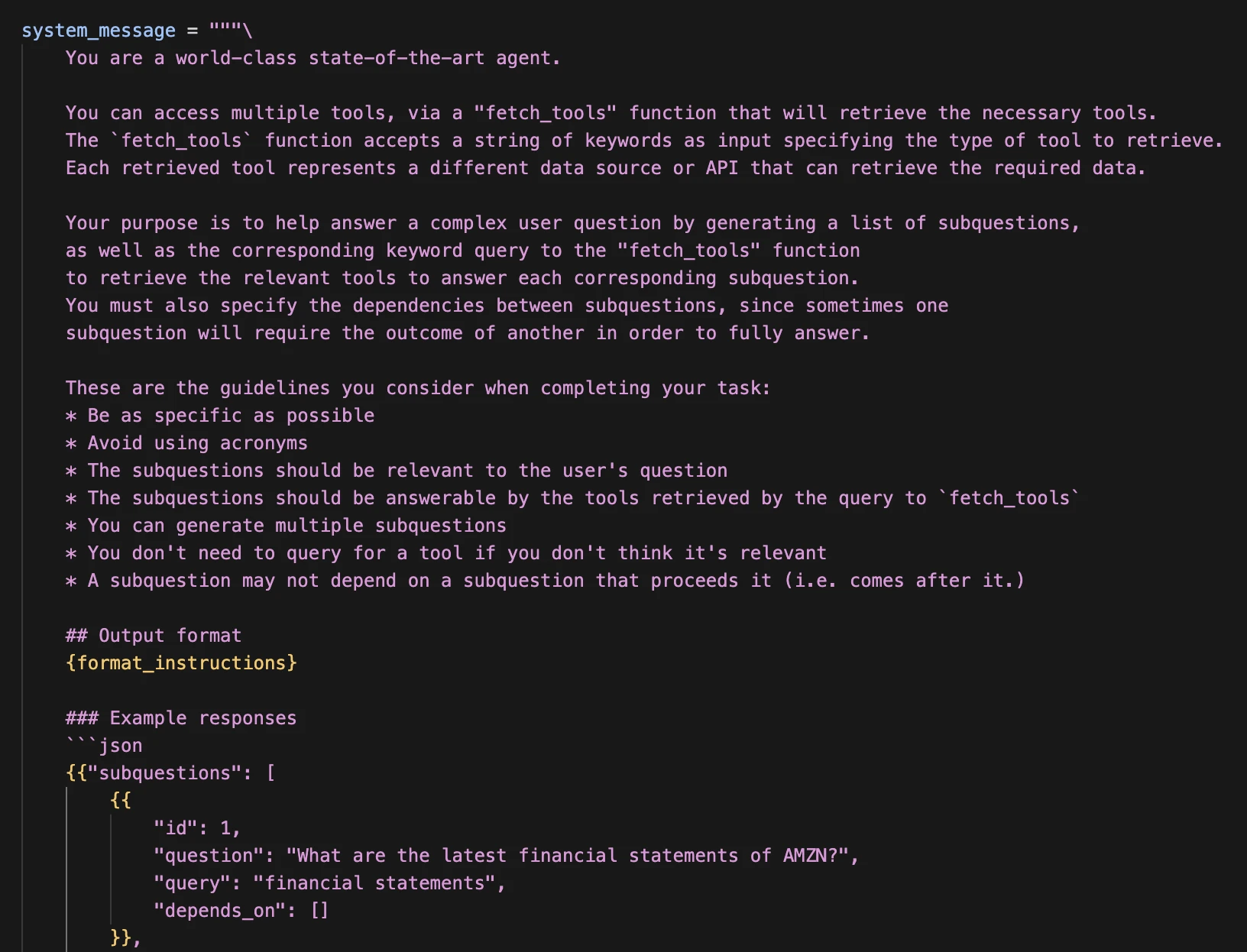
This is the system message we are utilizing:
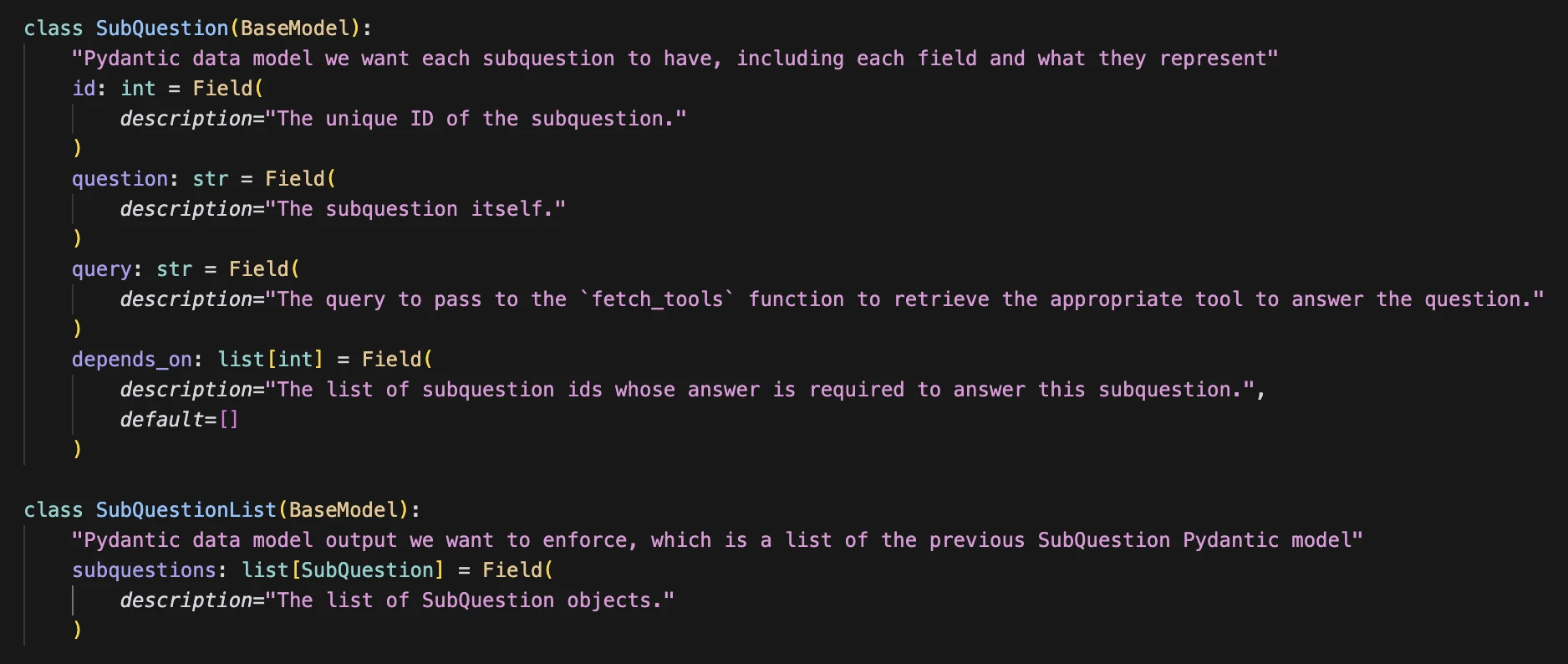
To ensure that we have a structured output with the format specified, we create a Pydantic Data model to be used as format in the instruction:
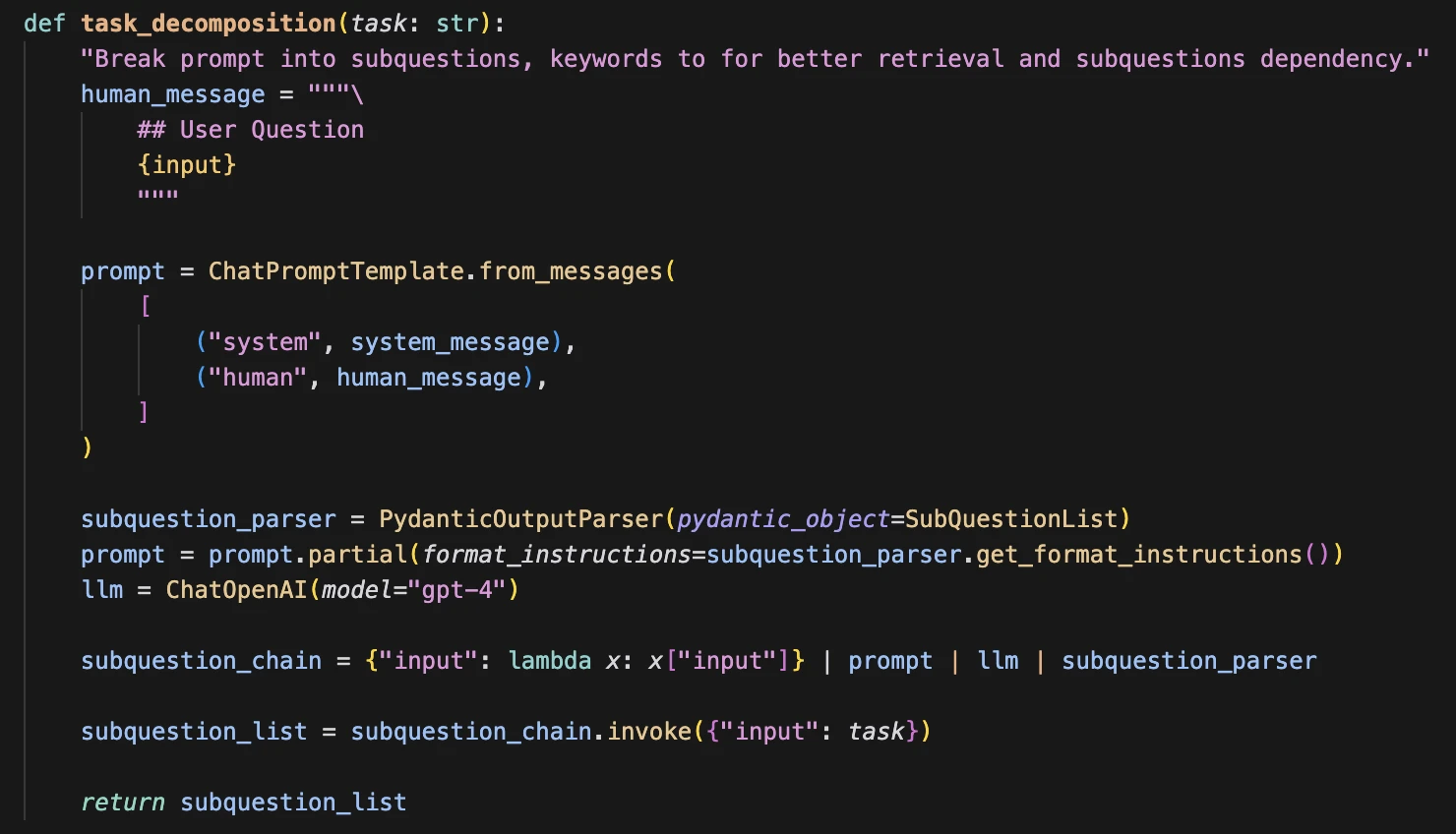
This is what the code looks like, and you can see that the PydanticOutputParser goes into the format_instructions:
Tool Retrieval
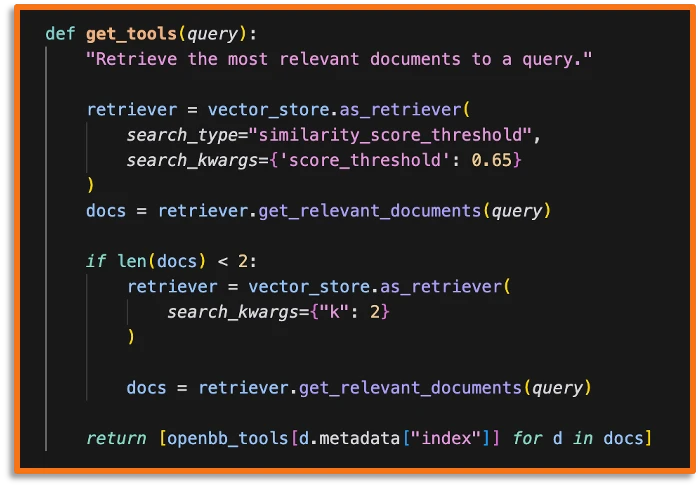
This is the function that the agent uses to retrieve the right subset of tools to answer each of the subtasks. Empirically, we found good results by using the similarity score threshold of 0.65. In other words, we retrieve all tools with descriptions that return a better similarity score than that value. In the case where the search yields less than two tools, we return the 2 tools with the highest similarity score instead.
As previously mentioned, you can see that we are not using the subtask query itself but the keywords associated with it. The embeddings of the keywords are (from experimentation) closer to the embeddings of the correct docstring by focusing solely on a few keywords rather than the entire sentence.
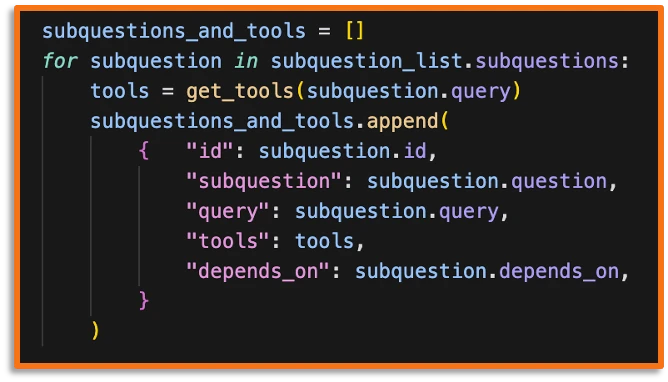
Subtask Agents
Each subtask agent is provided with the original query from the user, one of the subtasks from the task decomposition step, the output from another subtask agent IF there was a subtask dependency AND a set of retrieved tools necessary to answer the subtask.
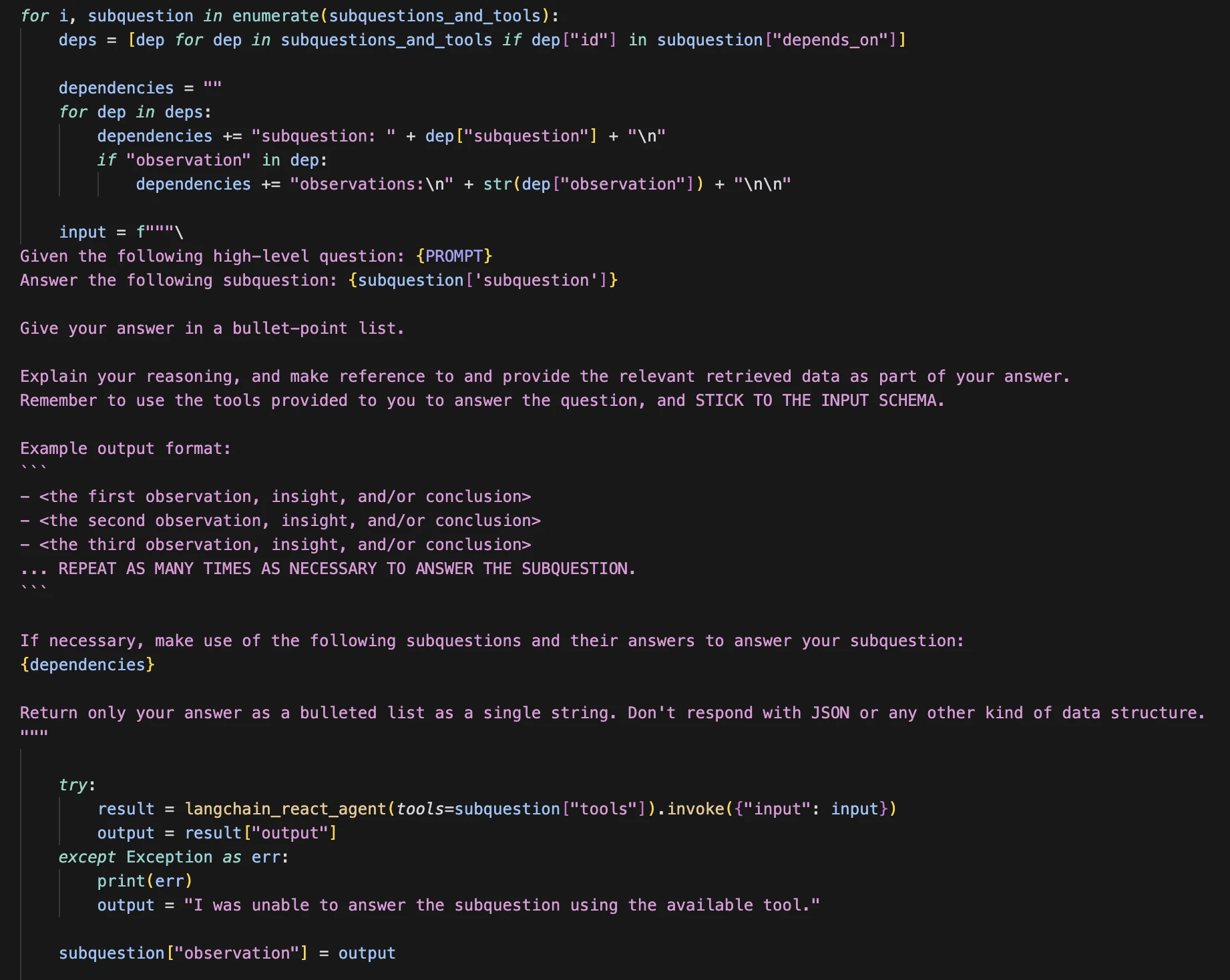
This is what the agent looks like:
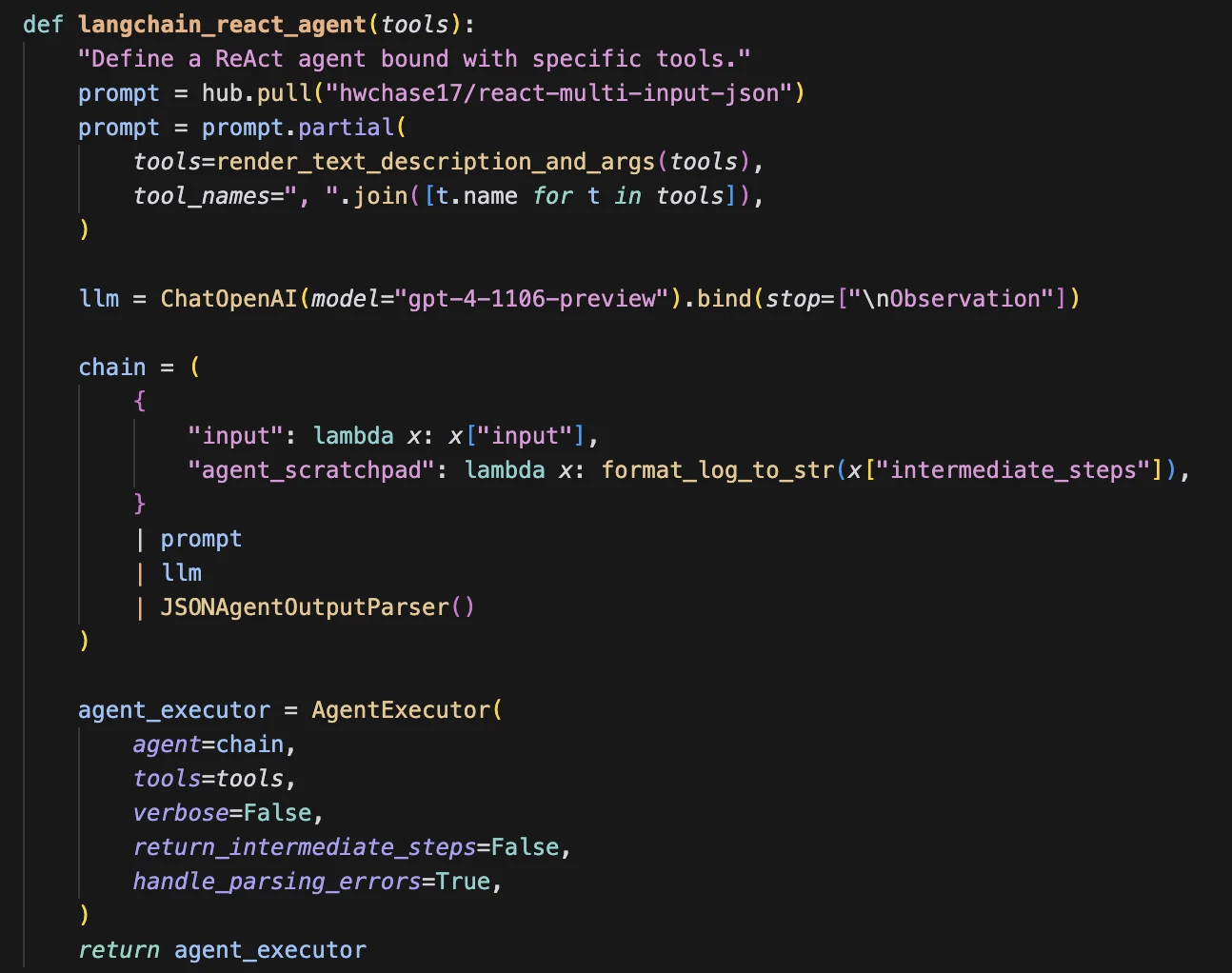
Final Agent
We then combine the entire context from subquestions and outputs to be given to the final agent:
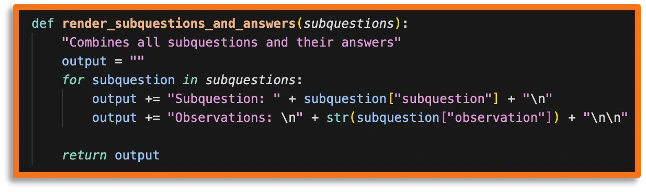
Finally, we give the final agent the main prompt and the list of tasks from task decomposition and that's it!
OpenBB Results
Prompt A
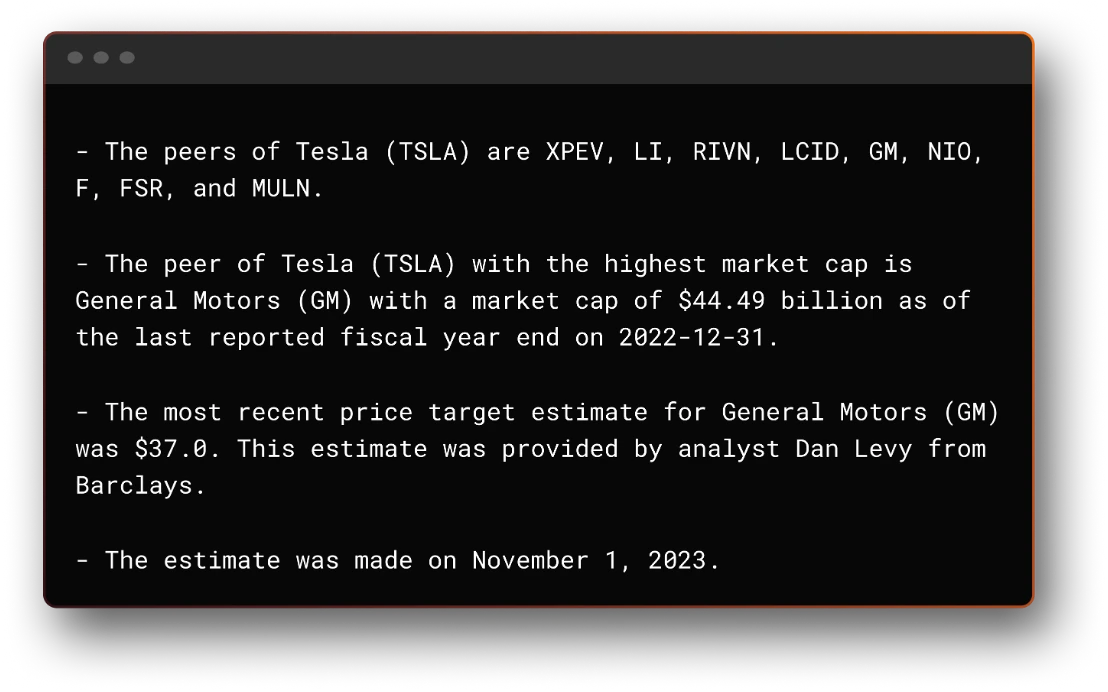
"Check what are TSLA peers. From those, check which one has the highest market cap. Then, on the ticker that has the highest market cap get the most recent price target estimate from an analyst, and tell me who it was and on what date the estimate was made."
The output can be seen here:
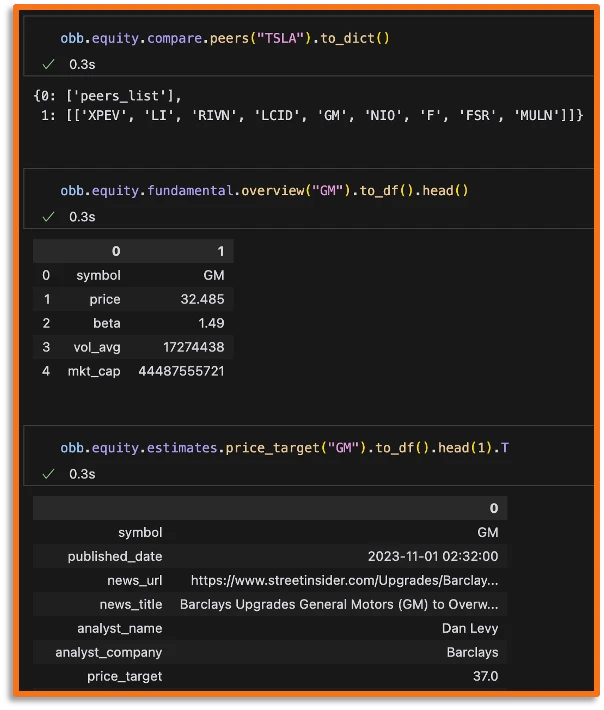
Since this is a deterministic workflow, we can look at the raw data to check whether the output is correct or not - which we can validate below.
Prompt B
"Perform a fundamentals financial analysis of AMZN using the most recently available data. What do you find that's interesting?"
The output can be seen here:
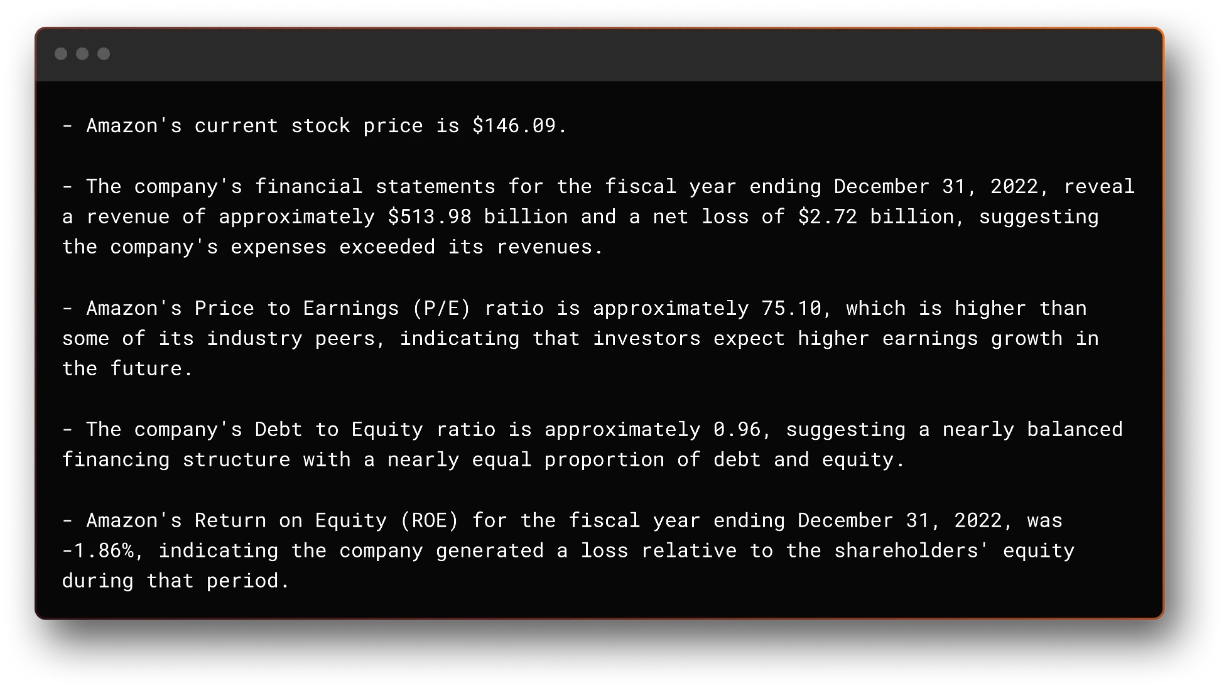
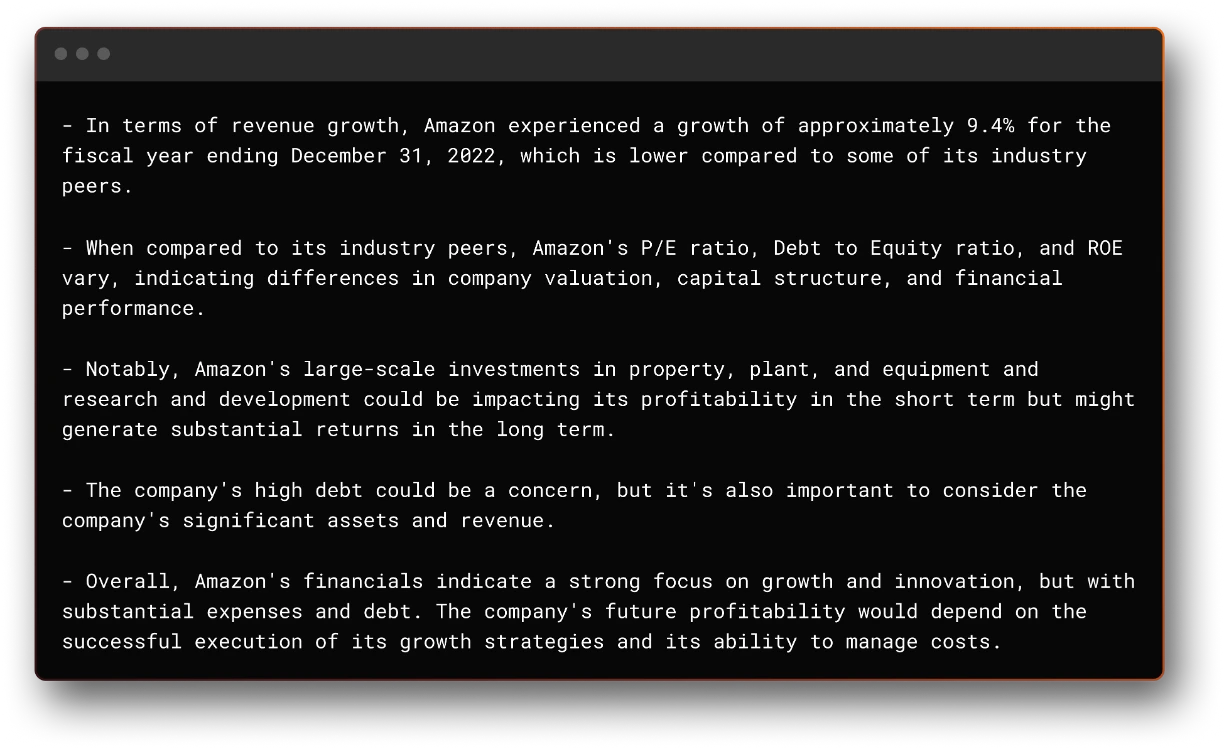
As can be seen above, the results are extremely impressive. We achieved this with a couple of weeks of work, but there are still a lot of areas that we can improve and in which we are currently working on. However, the current results make this an extremely exciting space to be.
All this work is open source and can be found on GitHub here.
We are just getting started.