How did we end up here?
The case for a firm-owned workspace in the age of AI.
A few weeks ago we had a presentation for AITEC members where we showed what's possible on OpenBB today. Before jumping into the demo, I wanted to contextualize how OpenBB became OpenBB.
So I created a presentation that walked through the journey shaping our product, our roadmap, and ultimately my/our world view.
This post is an attempt to criticize where we are as an industry and why I believe we can do more.
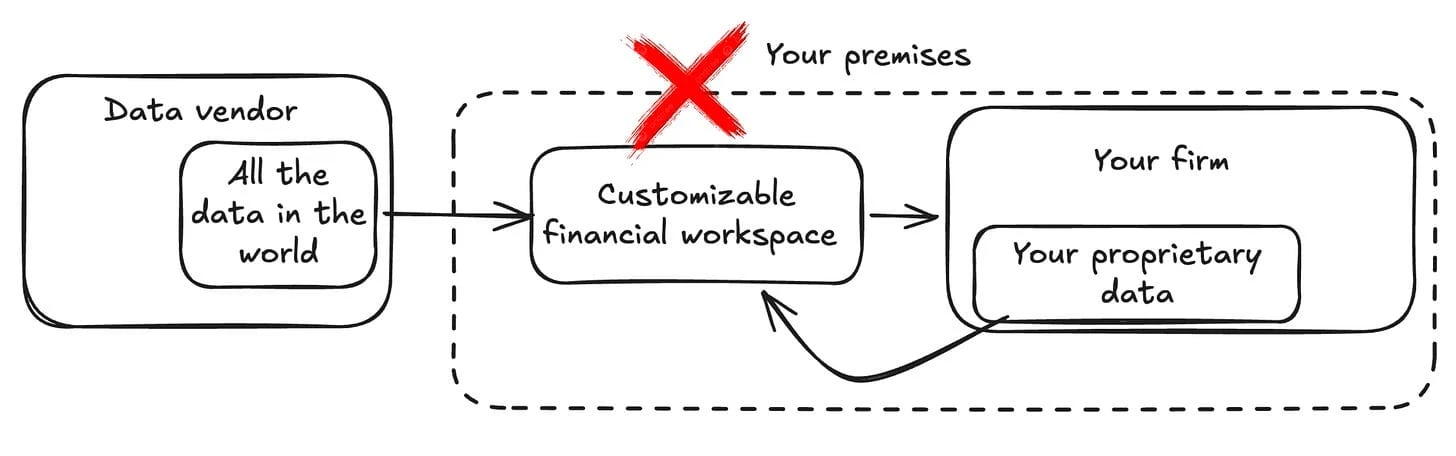
Financial firms should own the infrastructure where financial work happens.
I don't think that's a crazy statement. Yet we are very far from this reality.
By infrastructure, I don't mean just the UI or just the data. I mean the runtime. Where workflows execute and where AI inference happens.
This argument isn't anti-vendor. Vendors are essential. They generate and distribute rights-controlled market data. They ship analytics. They package workflows. The problem is what happens when the center of gravity of financial work lives on vendor infrastructure. Control boundaries blur. Internal context becomes second-class.
Vendor data is the main incentive. Business logic becomes coupled to someone else's platform decisions.
The Portage thesis report (AI Disruption of the Financial Services Data Industry) describes financial services as a uniquely idiosyncratic data environment where firms must mesh internal and external data across a complex and poorly documented web. It frames the current era as one of data abundance but insight scarcity. It also highlights the switching costs tied to entitlements, identifier dependencies, audit requirements, and downstream links. These are the mechanics of lock-in that show up as "we can't move, and we can't unify".
The conclusion is not "build everything yourself". It is: build or adopt the platform layer that keeps data, workflows, and AI inference inside a governed enterprise boundary, while remaining neutral to vendors and modular to change.
This essay follows my thinking process of what's wrong today, which ultimately leads to the vision of what OpenBB Workspace is, and isn't.
You own the interface where financial work happens. Data flows in. Intelligence runs inside. Your workflows are yours.
The bottleneck in modern finance is not the raw presence of data. It's the ability to turn overwhelming volume into usable decision-grade information. "Owning the interface" is shorthand for owning the place where context lives, where governance is enforced, and where the firm's proprietary understanding becomes reusable. If the workflow runtime is yours, internal context (positions, models, research, constraints, entitlements) can be treated as a first-class citizen. And so can anything else you wish to bring in.
AI accelerates this massively. Modern AI tooling is the first credible opportunity to simplify financial data access at scale, including by generating glue code across disparate formats and improving data quality continuously rather than diagnostically. Portage makes this argument explicitly. But it only compounds into durable advantage if the firm controls the environment where the simplification occurs.
But this is not where we are today.
Workflows happen on vendor infrastructure
When user activity, data queries, and workflow execution happen in vendor-managed environments, the firm gets productivity but yields sovereignty. The logging depth, runtime controls, operational policy, and evidence production are bounded by what the provider exposes.
No single vendor covers the full data universe
Equities, credit, macro, alternatives, and proprietary datasets come from different providers. Portage describes this universe as inherently diverse, spanning raw data generators, distributors, and analytic layers, with delivery mechanisms that range from feeds and APIs to terminals to cloud channels. So analysts and PMs stitch context across disconnected platforms to assemble a coherent view.
Fragmentation isn't just inconvenient. It breaks repeatability. Once workflows cross tool boundaries, intermediate assumptions and transformations become invisible or non-portable. That invisibility is a form of risk: you can't govern what you can't observe.
Internal data lacks first-class status
Uploading portfolios, proprietary datasets, or internal research is harder than it should be. Not because it's technologically hard, but because vendor platforms are optimized around vendor-controlled universes. Their incentives are the data margins. I wrote more about this here.
The firm's edge is not the vendor dataset. It is the firm's ability to combine vendor inputs with internal context. When internal data can't sit natively inside the same workspace, you end up with two realities: the vendor's (shared with every other firm) and your own (fully detached). Your reality is the one that matters. But when you're forced to model your world view through what a vendor provides, you hit limits in what you can do.
Business logic embeds in vendor platforms
Even when vendors are flexible, they ship a worldview: how data is mapped, what analytics are "standard", what a research workflow looks like, what gets logged, what gets shared. Firms operate within those constraints to remain compatible with the platform.
Portage's framing of the value chain shows how value accrues from rights-controlled sourcing through processing and analytics to distribution, where outputs get embedded in workflows. When workflow embedding is owned by the vendor, those dependencies become procedural and cultural. Portage also calls out the concrete mechanics that raise replacement costs: entitlements and data rights, identifier dependencies, audit requirements, and established links downstream.
API-level integration shifts the burden to the firm
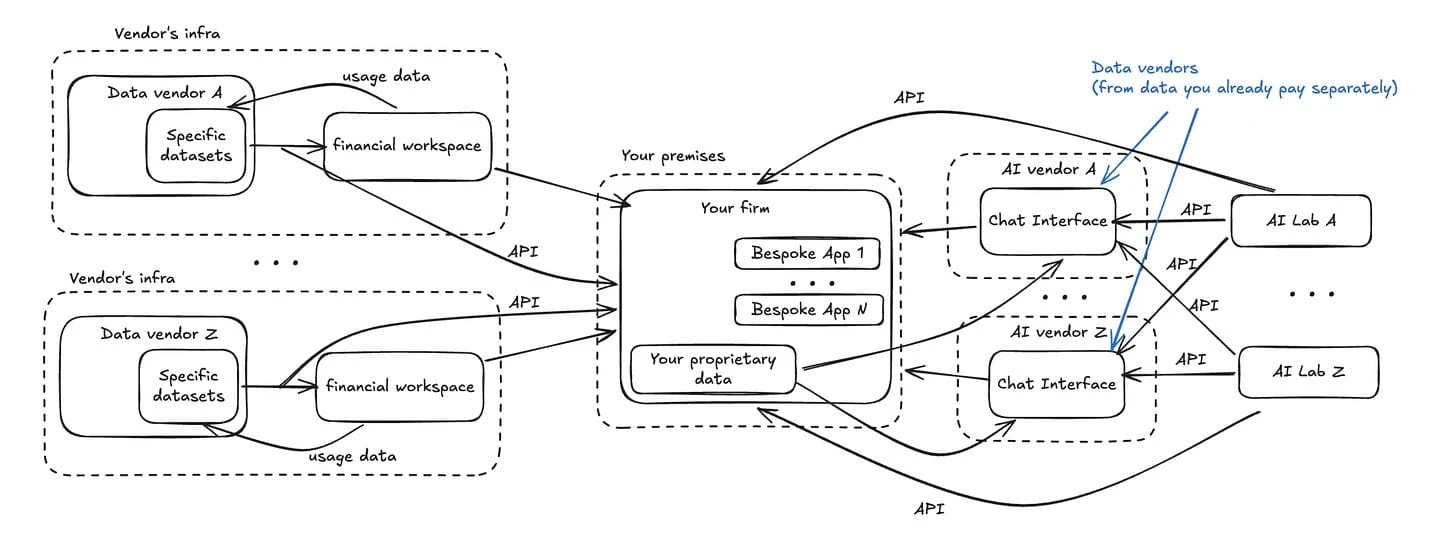
This is the cumulative picture. Multiple data vendors, each running their own infrastructure, each with their own financial workspace, each sending usage data back.
Your firm sits at the edge, receiving outputs from disconnected systems.
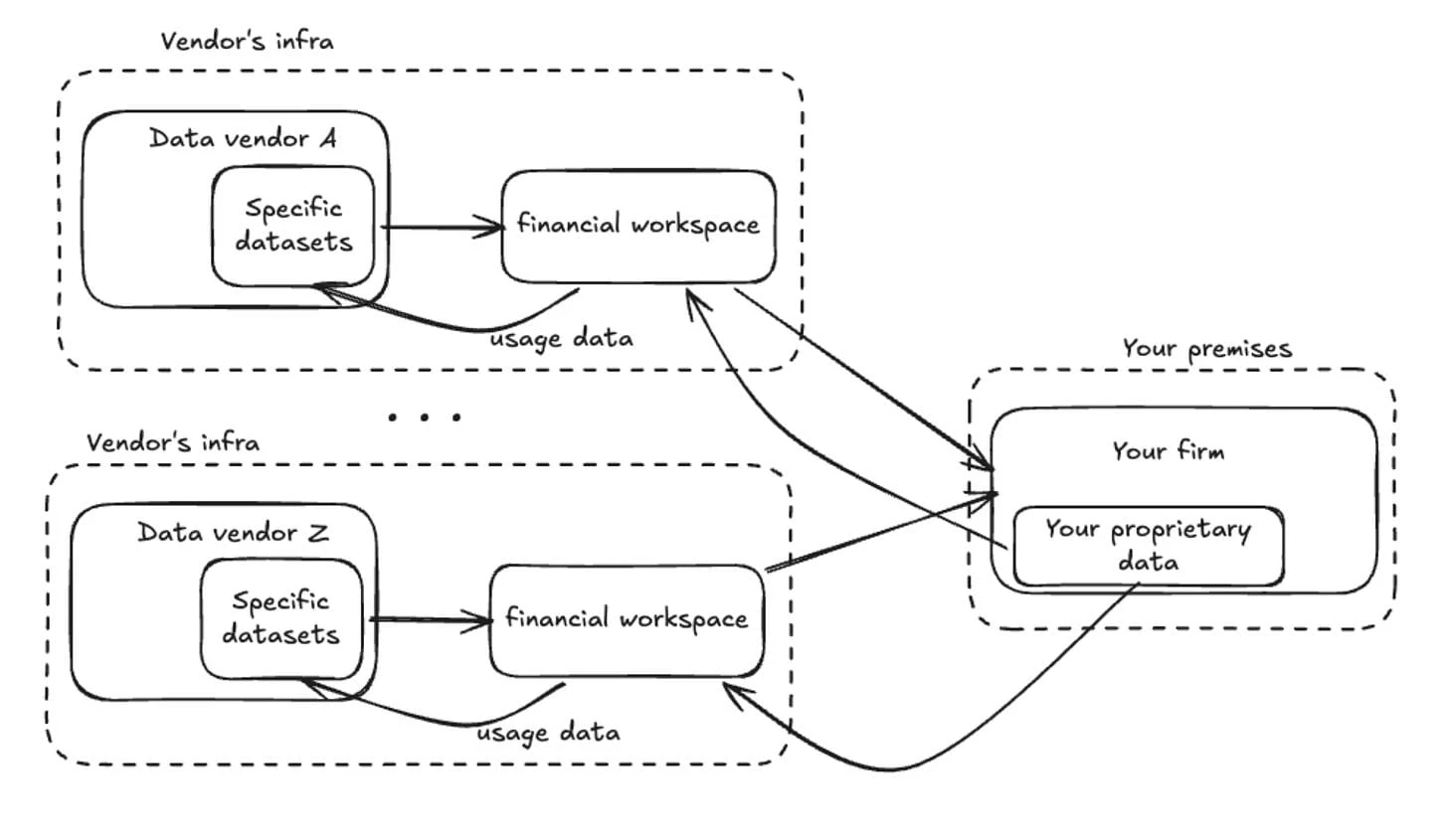
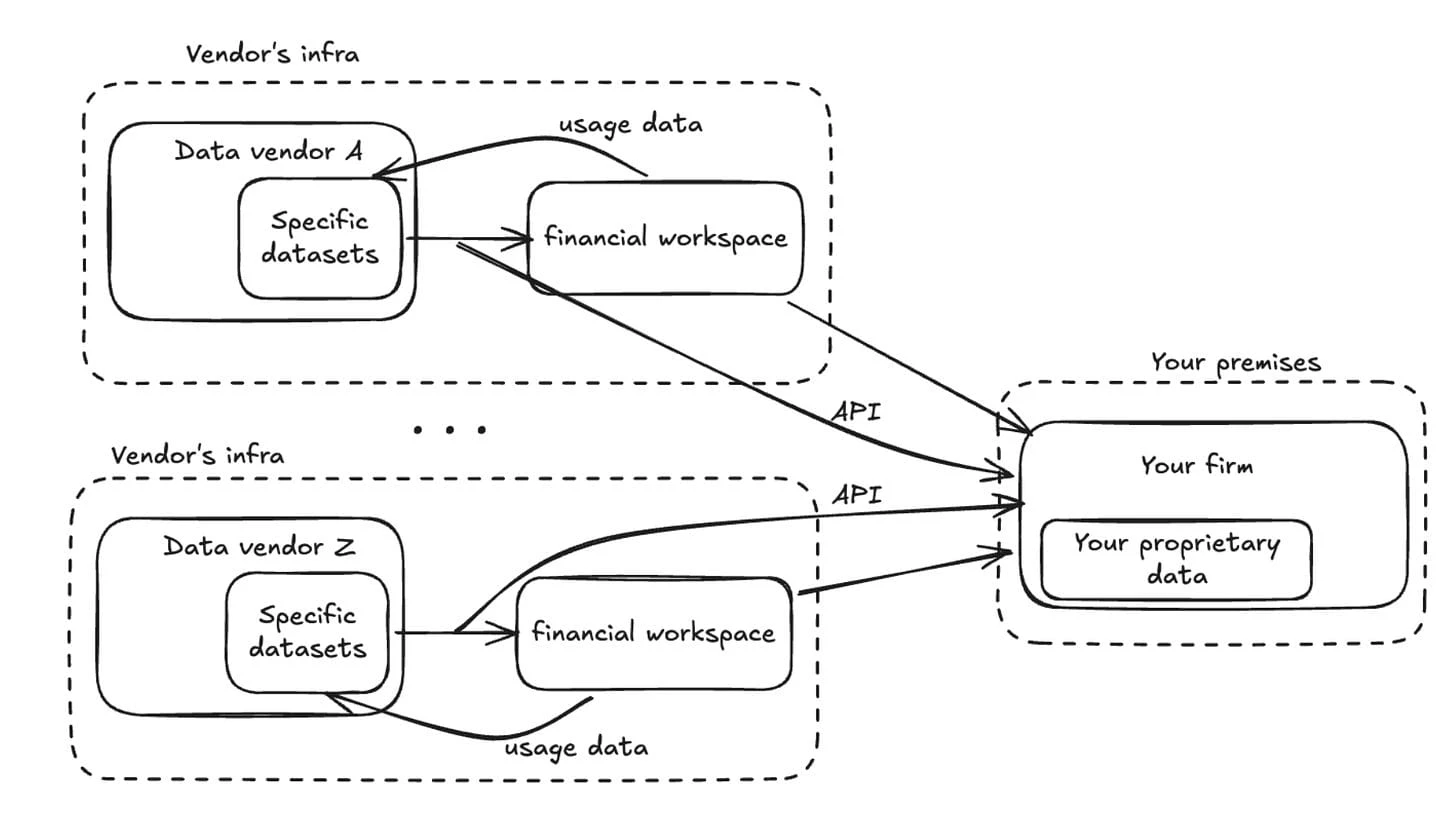
When the vendor platform can't be the workspace for the entire firm, the natural reaction is to consume vendor data as raw input and rebuild workflows internally.
Portage's investment thesis emphasizes developer-friendly APIs and distribution layers as where new winners will serve data and insights. That is the direction of travel. The terminal becomes less central. The enterprise integration layer becomes more central.
But API rebuilding moves the burden. Integration, governance, lifecycle management, entitlement enforcement, and auditability become the firm's job again, often without the benefit of a unified platform.
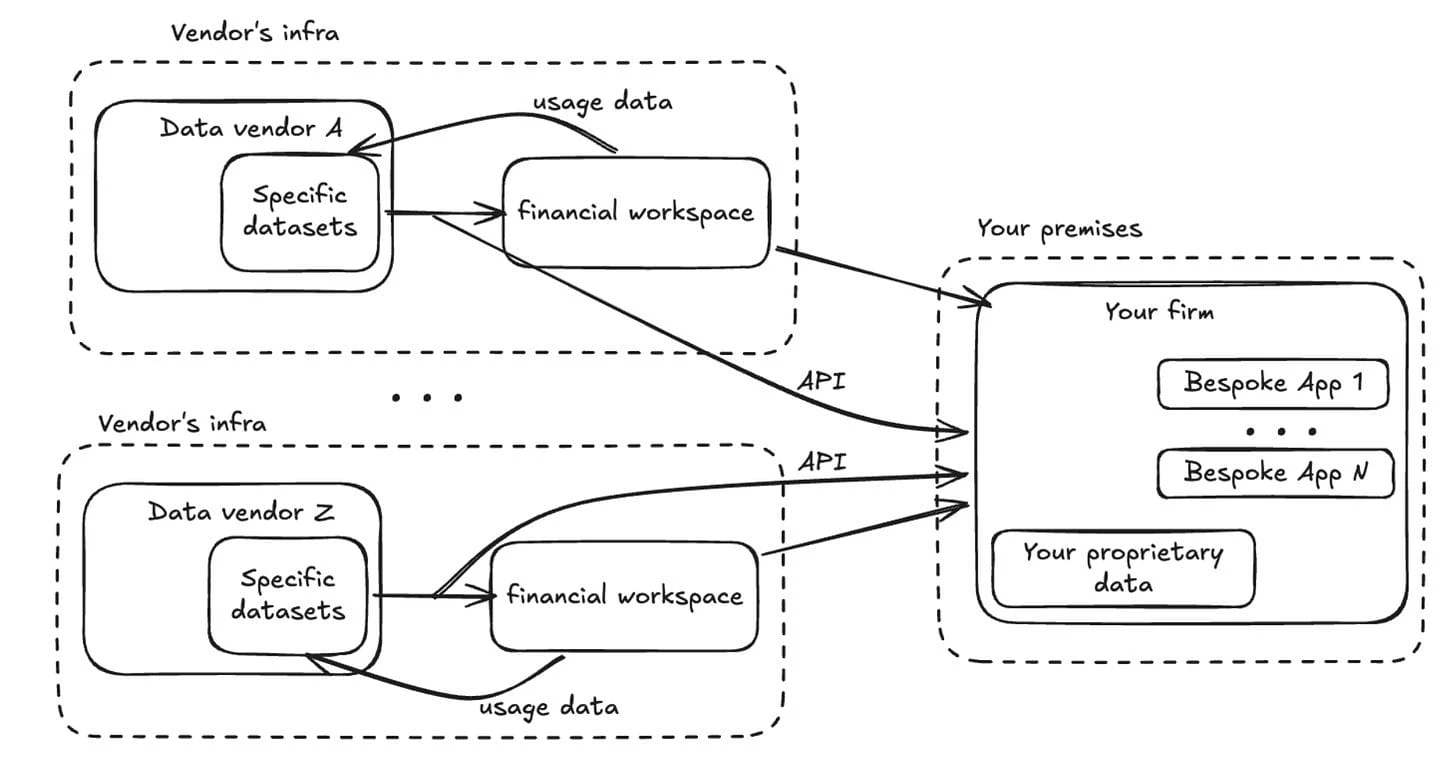
Point solutions proliferate
Once you start rebuilding from APIs, teams solve local pain fast. Portfolio tools, research dashboards, risk widgets, internal apps. Each gap gets patched. Each introduces its own stack, access controls, and operational overhead.
Portage notes that supporting layers like platform development, provenance, entitlements, and cloud delivery determine which point solutions can scale into standards. When those layers are absent or inconsistent, point solutions proliferate but none of them become shared infrastructure.
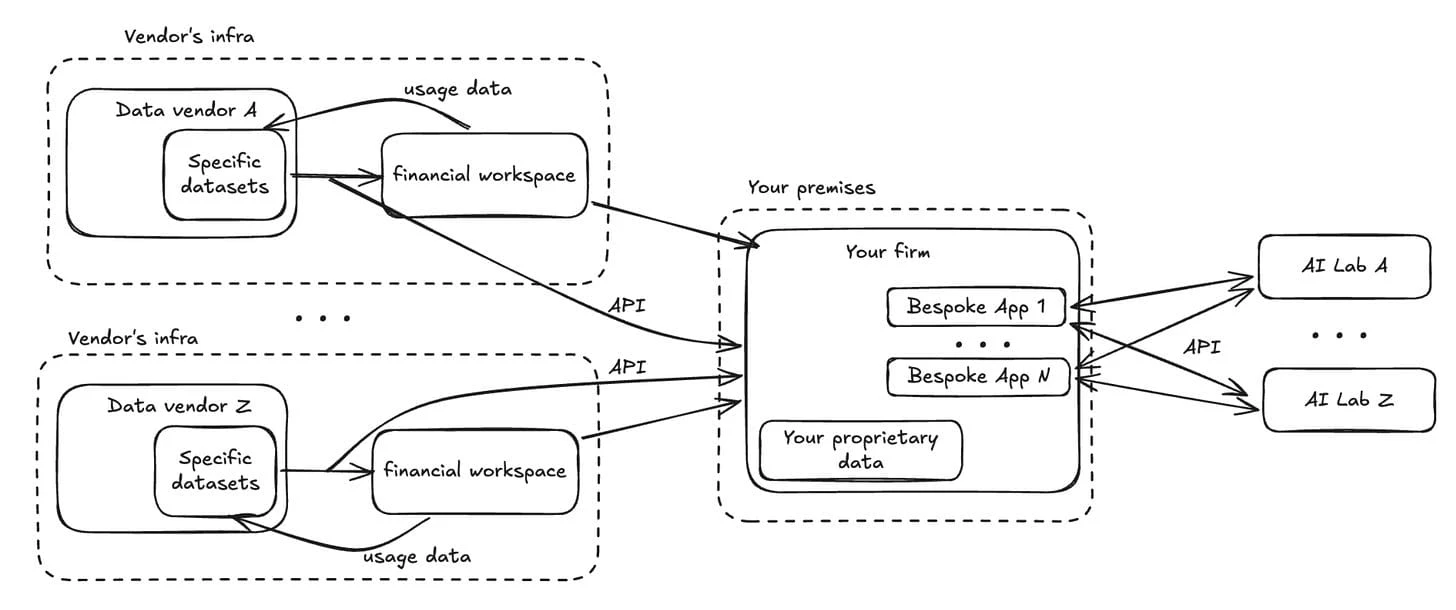
AI embeds separately across every system
Now the stack expands again. Each internal application integrates its own LLM provider, retrieval pipeline, prompt logic, and cost policy. Model governance becomes distributed across every app, with no central oversight.
If you implement AI as scattered per-app integrations, the governance functions that matter (model versioning, prompt auditing, retrieval policies, tool permissions) become nearly impossible to execute uniformly.
Third-party AI chat interfaces centralize control further
New entrants provide proprietary chat interfaces that sit above your systems. The firm now integrates and governs yet another vendor, often by uploading data that already exists elsewhere: internal research, portfolios, board materials, or licensed market data.
This creates two compounding problems.
First, if you upload licensed data into a third-party AI environment, you must be able to defend that it remains within permitted use, and you must prove entitlements and control propagation. That is difficult without a firm-owned policy and logging plane. Exchange policy documents restrict redistribution. A firm that uploads licensed feeds into an uncontrolled UI is creating a defensibility problem it may not be able to unwind.
Second, regulatory-grade auditability is easier when inference is inside your governed runtime. Even if a provider doesn't log prompts, the firm still needs its own evidence. Who accessed what, what context was used, what output influenced what artifact, and how retention applies. Especially under record-keeping regimes that emphasize audit trails and producibility.
What we have built as an industry is not one stack. It is multiple stacks stitched together. Each with its own entitlements, its own logging, its own identity, its own policy logic.
And AI pours gasoline on that fragmentation.
It doesn't have to be this way
But it doesn't have to be this way.
Consolidate vendor data, proprietary datasets, internal apps, and AI into a single governed environment. Nothing leaves your infrastructure, including model inference.
Now the concrete "how".
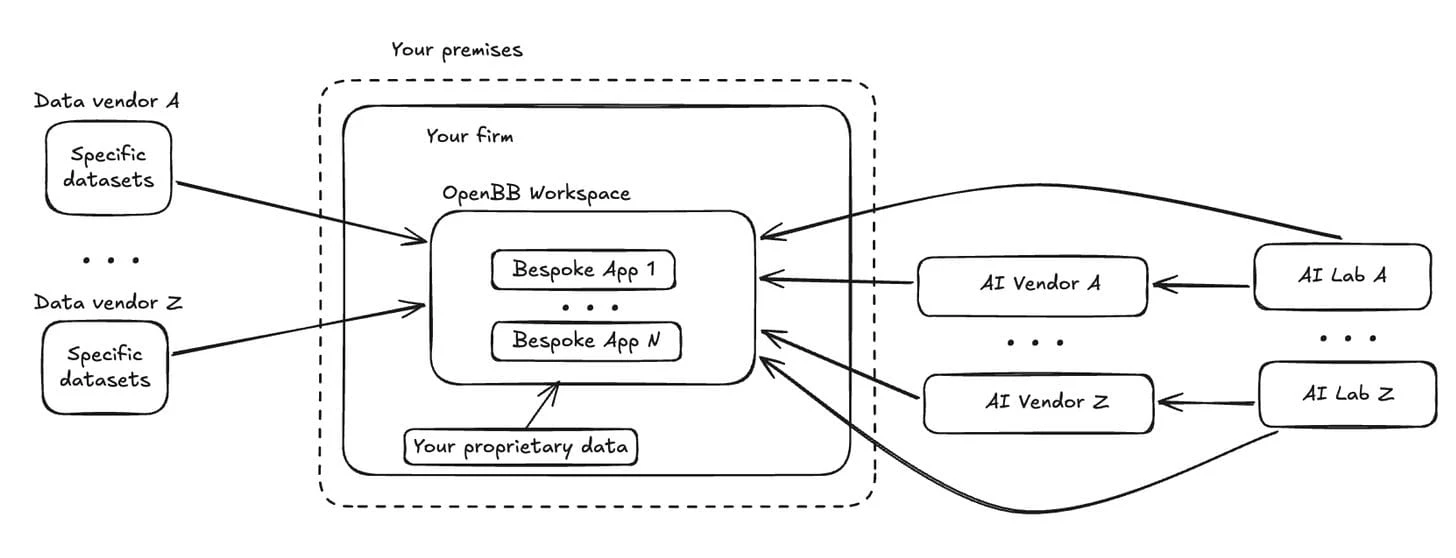
A platform architecture that keeps firms sovereign. At the core is a simple separation: vendors provide inputs (raw data, analytics, or inference like LLMs). The firm owns the workspace where decisions are made. And the workspace has no external context by default.
The owned-runtime model in practice: vendor inputs flow in, internal data is native, workflows run inside a controlled environment, and AI inference is routed through a governed gateway that enforces policy and produces audit-grade telemetry.
The components: internal systems and external vendors as data sources. A firm-controlled environment with SSO/identity, RBAC/ABAC and entitlements policy. A data substrate in open formats. A firm-owned semantic layer for IDs, mappings, and metrics. Firm-owned workflows (apps, dashboards, agents). A model gateway handling routing, quotas, and evals with a controlled inference runtime. Immutable audit trail and observability across logs, metrics, and traces.
What flows through this: any market data (exchanges, filings, news, transcripts, alternatives), your portfolio positions (without uploading to third parties), third-party AI agent integrations, and your additional context (research, risk policy, signals).
-
Control. SSO, RBAC, logs, and permissioning standardized across workflows. Alignment with modern security models and with record-keeping expectations that assume you can produce and prove what happened.
-
Neutrality. Connect any data vendor without changing the interface layer. Neutrality becomes real when entitlements and identifiers are abstracted into a firm-owned semantic and policy layer. Portage notes that entitlements and identifier dependencies are what tie customers to incumbents. Open formats and vendor-neutral observability reduce lock-in at the storage and monitoring layers.
-
Enterprise-ready. Apps and agents built by one team can be securely shared across the firm. Shared primitives, shared guardrails, shared operational standards. Without that, point solutions don't become products. They become liabilities.
-
AI governance. Model orchestration, usage tracking, and inference policies managed centrally. Centralizing inference through a model gateway turns governance into something you can actually execute.
If I had to reduce this into a practical, stack-agnostic set of actions:
Build a governed data substrate that supports both structured and unstructured inputs. Documents, transcripts, and other scarce unstructured sources need to live in the same environment as market feeds. If they don't, your AI can only reason over half your world-view.
Favor open formats and decoupled compute so data remains portable and AI-enabled without rewriting your world.
Implement entitlements, provenance, and identifier mapping as first-class platform services. These are the mechanics that create lock-in. If this logic lives inside every app, you will never become vendor-neutral.
Build immutable audit trails for the artifacts that matter (research notes, generated outputs that enter a workflow, approvals, exports) and keep the link from "who asked" to "what data was accessed" to "what output was produced."
Treat third-party AI chat interfaces as edges, not centers. Use them through governance boundaries. Where external AI must be used, rely on enterprise configurations that support constraints like non-training by default and optional zero retention. But keep the firm's own logs and policies as the source of truth.
And if you want an infrastructure kickstart for this journey, reach out to me. We know a thing or two.