You can't prompt your way to an AI Bloomberg Terminal
Primitives beat prompts. Every time. BI tools are the most underrated foundation for GenUI in finance.
Hear me out…
Before you can generate a useful financial interface, three things need to be true.
-
You need accurate, governed data access where you actually know where the data comes from and whether it can be trusted.
-
You need composable visual components that are consistent and on-brand, not generated newly every time. And please don't tell me that everything will be chat-based because you will still want charts in that chat, and then maybe a table, and ohhh - you are back in the workspace/dashboard realm.
-
And you need enterprise controls, permissions, theming, audit trails, the stuff that makes software deployable inside a real organization.
BI tools have all three.
They spent decades getting them right.
The reason nobody talks about PowerBI, Tableau or Looker in the context of finance GenUI is because the interface isn't necessarily sexy and it requires a data team, a BI developer, and days of back-and-forth.
But the primitives they have are the right ones.
I think about this in three stages, and you can see it in the changelog/roadmap of our own product.
Stage 1: BI-like foundation
The first is having a BI-like foundation with a library of trusted, customizable components: Charts, tables, widgets, each connected to governed data, each themeable to match a firm's preferences.
A hedge fund and a bank have different aesthetics, different data sources, different definitions of what "standard" even means. The foundation has to accommodate that before AI touches any of it.
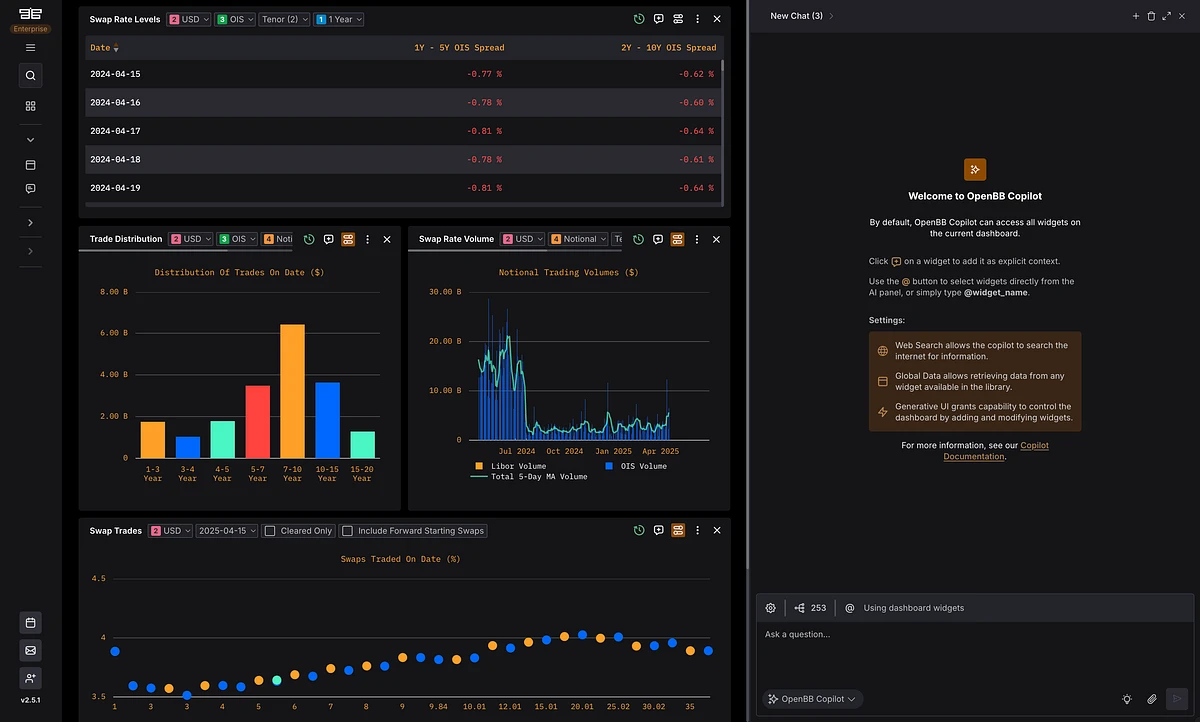
Stage 2: Incremental GenUI
The second stage is incremental GenUI.
An agent surfaces a relevant data point mid-conversation and the user adds it to their workspace with one click.
A copilot suggests changing a parameter on an existing widget and the user approves it.
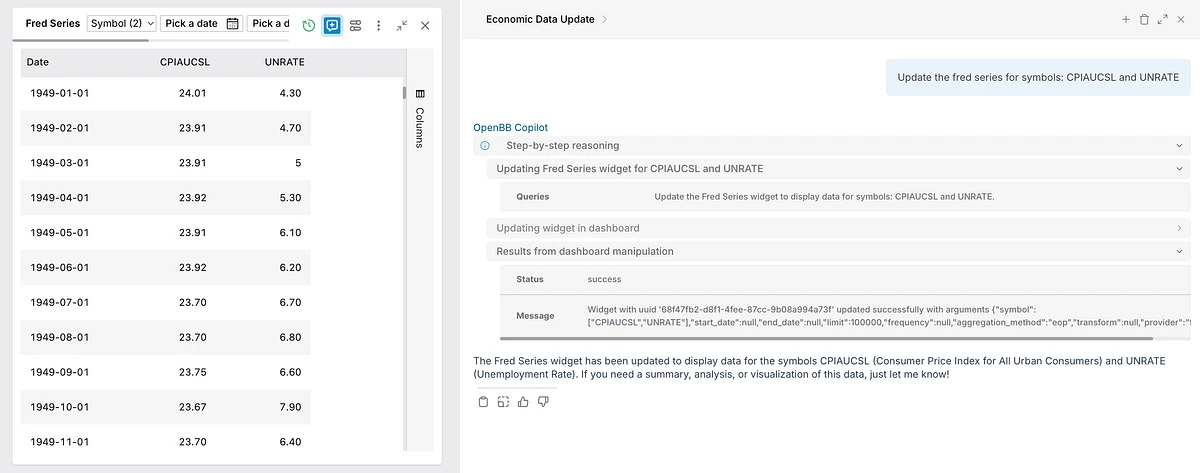
An MCP or API call triggers a suggestion: "I found a widget that matches what you're looking for, want to add it?"
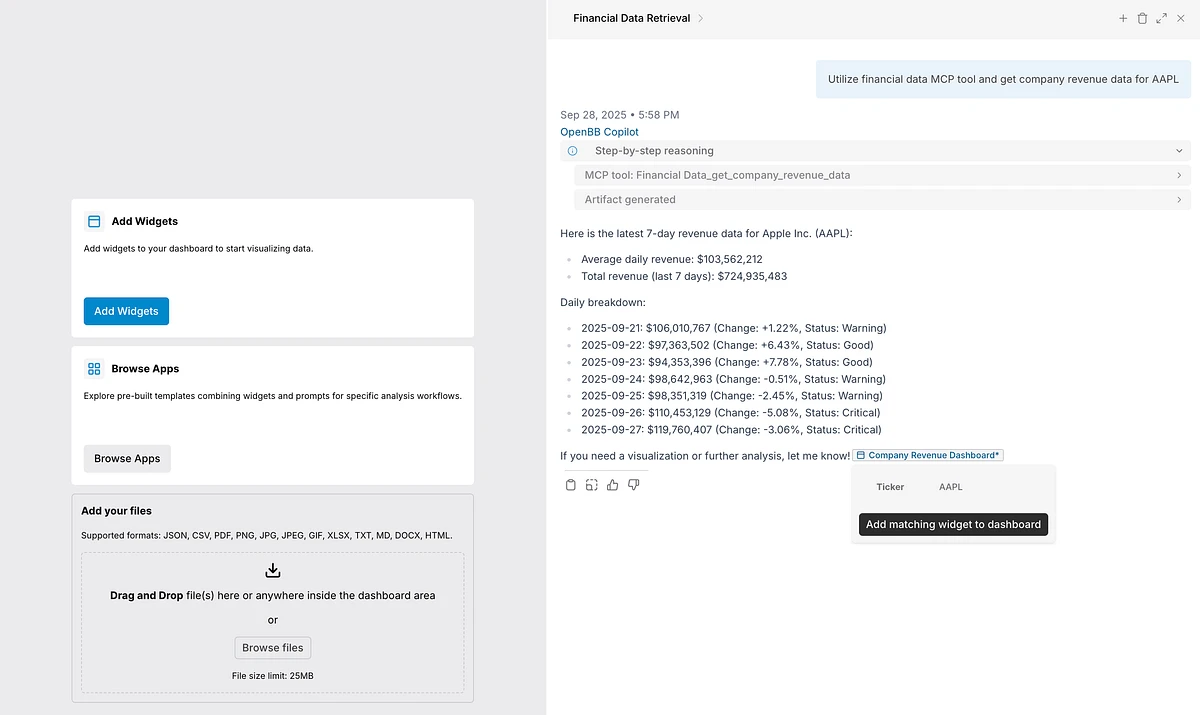
AI suggests whilst user remains in control. And everything added stays grounded in the validated primitives from stage one.
Stage 3: Full GenUI
The third stage is full GenUI.
A copilot that composes an entire dashboard from the trusted components a firm has already defined.
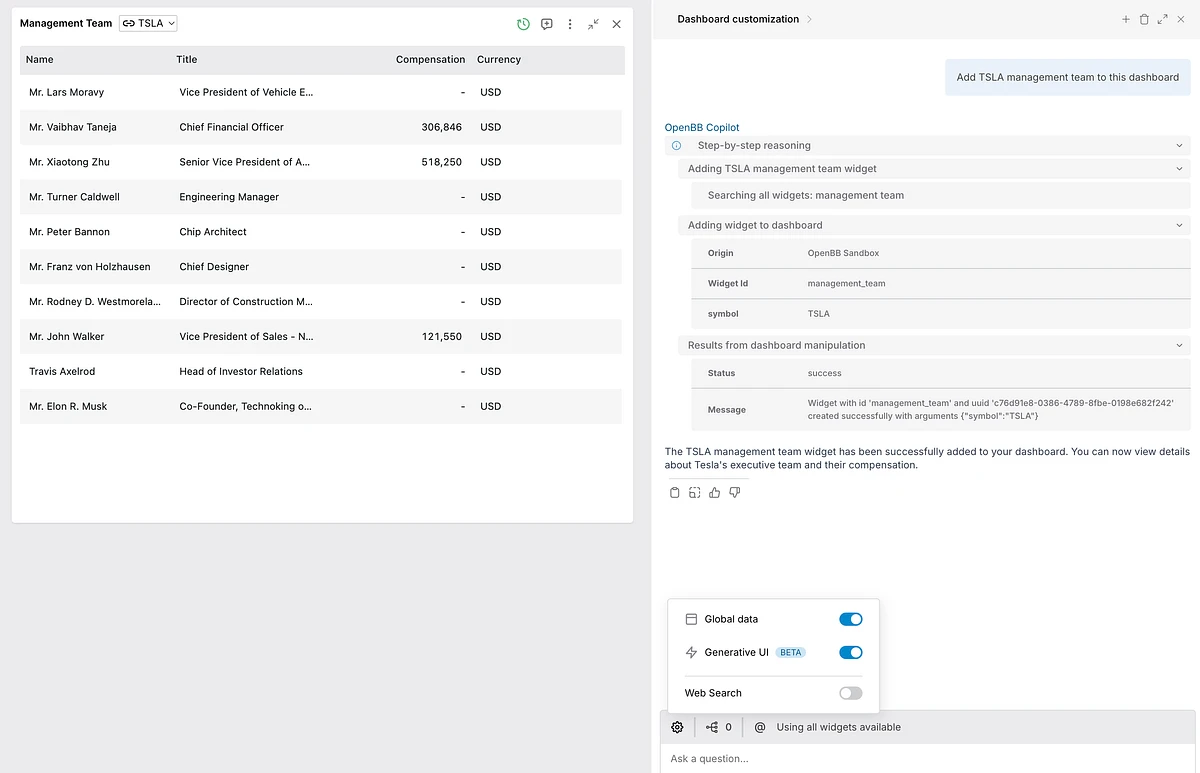
It can also generate derived artifacts, like an HTML report built from widgets currently on the dashboard, pulling from live validated components rather than regenerating data from scratch. Example here.
In this last stage, I don't mean "a BI tool with a chatbot bolted on". Traditional BI copilots are retrofitted, AI layered on top of tools designed for point-and-click workflows. What I'm describing is the inverse: a workspace built agent-native from the start, where AI is the primary interaction layer and BI-quality primitives are the substrate it operates on.
The AI isn't a feature added to a dashboard builder. The dashboard is a surface that an AI knows how to use from the start. Truly AI-native.
What if you generated everything on the fly?
There are a few issues with the approach, here are some of them:
-
Predictability. When everything is generated fresh you don't know what you're going to get. Different phrasings produce different layouts, different components, different visual structures. Fine for a personal tool, but not so much for a trading desk that needs to know exactly what it's looking at every time. But only if you had the right primitives, right?
-
Data trust. Ad-hoc AI-generated ETL is not a substitute for governed data infrastructure. Firms investing seriously in their context layer, cleaning data, defining metrics, building lineage, aren't doing that so an AI can ignore it and vibe-code on top. I'm once again saying, YOU NEED THE RIGHT PRIMITIVES.
-
Latency. Generating all primitives on the fly is slow. No stable component layer means nothing can be pre-validated, pre-tested, or pre-styled. Every generation starts from zero. There's a reason why having the right primitives is important (again!).
-
User control: What gets generated on the fly is customizable for the developer, duh, but what about the end user? What if they want a different view with that very same data? What if they want to hover on a feed and see where the data comes from and latest request? WHERE ARE THESE PRIMITIVES
-
Enterprise controls: I probably don't need to go over this one, as it's evident..
The Perplexity Bloomberg demo
The Perplexity Bloomberg demo is a perfect illustration of this.
Someone recently used Perplexity Computer to build a Bloomberg Terminal clone, allegedly.
So my fundamental question is how does the data licensing actually work here?
Does Perplexity default to utilizing whatever data is open and accessible out there? This is fine for SEC filings, but not so much for Yahoo Finance as they would need redistribution rights to do so.
We got a cease & desist in the early days of OpenBB Workspace, and we weren't even the ones accessing the data - the end users were when they accessed it from their machines.

For the content that gets generated on the fly, do they have redistribution on that data? (I know from a credible source that for some of it at least they don't)
I mean, how does it work if I use it to generate a personal dashboard for myself - but more importantly, how does it work when I generate a software for others?
Is the data static, or are they dynamic? Hitting the endpoint from the data vendor? If so, which API key are they using, Perplexity's one?
Most financial data vendors are already "funny" about software that allows export, because export is legally grey when it comes to redistribution.
But then there's data that cannot be redistributed, e.g. S&P Global usually doesn't allow redistribution or user downloads, unless there's a custom negotiation for a distribution license done on a client by client basis. And that is for data that they even have the rights to redistribute (like high-level consensus because it's derived data), but some data they purely can't (e.g. granular estimates, as these are owned by the sell-side brokers who contributed them).
So I have a lot of questions about how this actually works to be used in an enterprise context.
When you generate everything on the fly, data quality and data rights both become the model's problem. The same model that doesn't have access to the context in which you stroke a deal with the vendor, the same model that doesn't know how the generated dashboard will be used and by whom (e.g. for real-time data you need to pay exchanges and that price depends on whether you are professional/retail investor).
So, you either believe data teams are pointless and the context layer that firms are building means nothing, or you accept that generating interfaces like this without connecting them to governed data is just not going to happen anytime soon.
Or maybe you just need the right primitives?