My AI agent wrote a research paper about the code it wrote
It researched the SOTA, cited related work, drew architecture diagrams, and produced a 6-page IEEE-style paper.
A few weeks ago I shared how I built a reverse card scanner for Pokemon Cards without writing a single line of code.
Demo here or you can test it here: https://pokvault.com/scanner
Claude Code did the entire implementation. I literally did not write a single line of code. We are talking about a full end-to-end ML pipeline (corner detection, CLIP embeddings, quantization, retrieval, etc.).
As CC was working on this, we were brainstorming the implementation. I was understanding his thinking process better and learning as we went. I've done some computer vision in the past, but not a lot.
First, I started with this golden sample:

I basically let Claude Code iterate on the algo until it recognized this being Mewtwo #059 from Scarlet & Violet.
Then I learned the decisions it made and why it made them. Bear in mind this is an extremely simple example, but it allowed me to test the vision embeddings (not the corner detection).
Then I went to a harder example: a picture of a card on a clean background, centered but with surroundings. This allowed me to test the corner detection algo.
Then I went into a weird angle, such as this:

you can see my dog tail in the corner
This took muuuch longer.
Once it got it, obviously it was overfit to this example. So then I gave it a "Test set" that it would need to run against after each algorithm update.
And it got it.
I was actually proud of the outcome. Even my wife was impressed, which isn't a lot, but it's honest work 🚜😎
(there's always a but!)
I didn't quite like the fact that I didn't have a way to follow what the agent had done in terms of the algorithm.
In the end, it was a lot of code. Including algorithms that were implemented but not used because of performance (e.g. YOLOv9 card detector).
So I needed to come up with a way to learn about what happened.
Duh, just ask the agent about it. And learn from it.
Yes sure, but what if I wanted to revisit this in a few months? Only a fraction of that knowledge would be retained…
So I needed to find a way to write down this implementation, but also what was tested, what other algorithms exist, how this one compares, and also keep it to like 6 pages…
And that's when 💡
There's one universal way to communicate technical work that includes related work, methodology, evaluation, and citations!
A IEEE-style paper!
"Claude, write an IEEE-style report of this Pokémon card scanners algorithm. Make no mistakes"
And it did, I open sourced it here: https://didierrlopes.github.io/pokemon-card-scanner-paper/
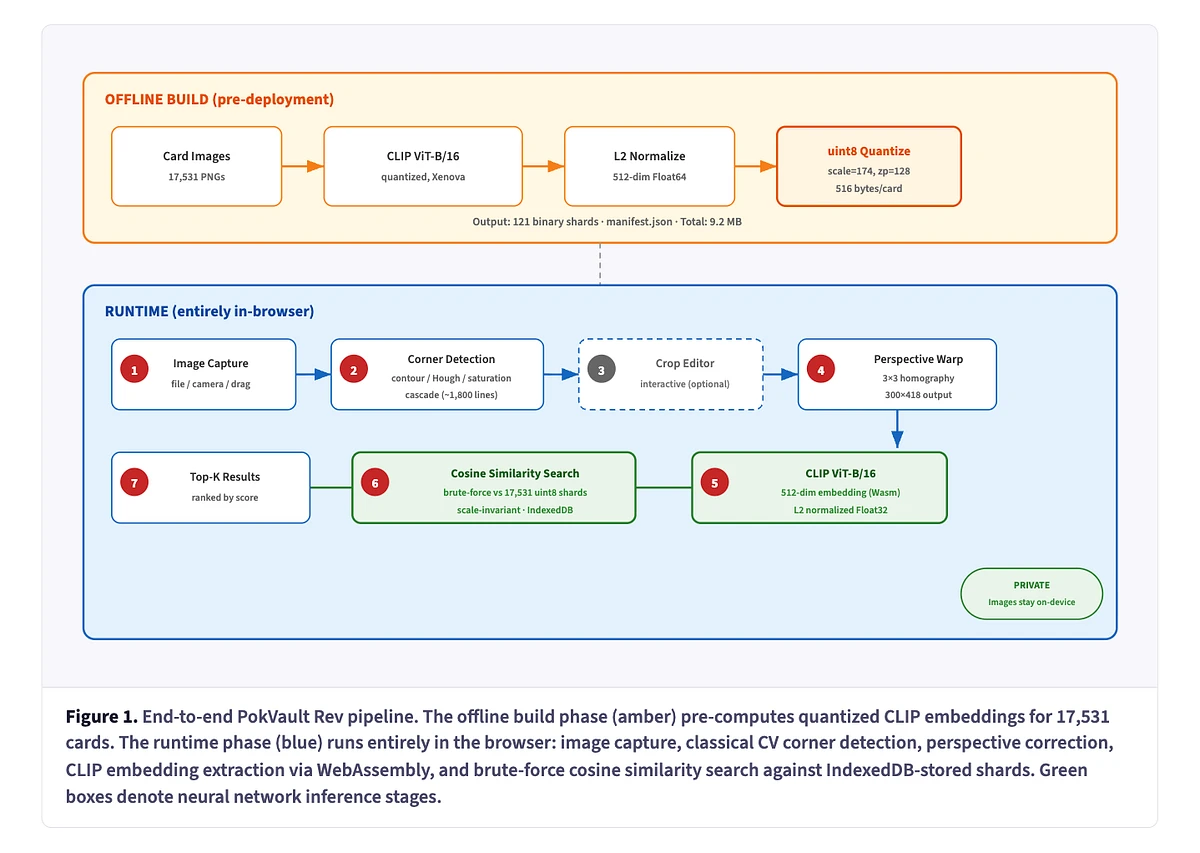
The output was… uhhh.. incredible.
It gave me a much better understanding of the current SOTA algos in the domain; a clear understanding of the architecture (offline and online), most of which we had discussed but seeing it in a diagram was cool; and ultimately a better understanding of what it was doing.
After that first draft of the paper, I spawned another agent to find issues in the paper based on the current codebase, and it made that first draft better as it was able to find inaccuracies and missing nuances!
The value of "the what" is growing
When I worked on side projects in the past, I first had the idea ("the what") and then spent most of the time on "the how".
But, "the how" seems to be fading?
In this case, the goal (i.e. idea) was to be able to scan a Pokémon card and detect which card it corresponded to.
Did it matter if it used YOLOv9 for card detection or not? Did it matter if we did quantization? Not really…
The value of the what is growing exponentially, in an age where the cost of building software goes to 0.
What problem are we solving? What should the user experience be? What trade-offs matter (e.g. being able to run offline was important for me as the card shop I go to is underground and I don't have signal in there lol).
It's still important to have some understanding of the how, particularly if you are a domain expert, as then you can guide the agent. For instance, when the agent was detecting the Mewtwo card, the first set of cards that showed up in the similarity search weren't purple. So I knew the embeddings of the card and the set of cards algorithms didn't pass through the same pipeline, because even if the algorithm wasn't very good, I would have expected, at the bare minimum, to detect purple cards when we used that reference input.
Academic papers as a reward function
Anyway… this made me think of something else.
Academic papers have a built-in reward function.
Peer review.
A community of experts whose job is to verify claims, challenge methodology, and reject work that doesn't meet the bar. That's essentially a human-in-the-loop evaluation system for technical accuracy.
Now imagine agents writing papers. Submitting them. Getting feedback. Iterating. Resubmitting.
That's an RL loop with human peer reviewers as the reward signal.
We already have functioning loops like this in other domains.
- Code review bots submit PRs, get feedback from human reviewers, and improve.
- RLHF trains language models using human preference signals.
- AlphaGo played itself millions of times with win/loss as the only reward.
The pattern works when the reward signal is clear and verifiable.
Academic peer review fits that pattern. Accept, revise, reject - that's a clean signal.
The methodology is either sound or it isn't. The claims are either supported or they aren't.
And as agents get better at producing rigorous work, they start becoming useful as reviewers too. Catching statistical errors, flagging missing citations, verifying reproducibility claims. At first, things that are tedious for humans but trivial for machines.
But it doesn't stop at mechanical verification.
As agents produce work that consistently passes human review, they earn credibility in the same way junior researchers do. First they assist. Then they co-review. Then they review independently, with humans auditing the reviewers instead of doing every review themselves.
Algorithms writing papers about themselves. Other algorithms reviewing those papers. Humans setting the standards and auditing the process.
It sounds circular. But so is the system we already have. Researchers review other researchers. The loop works not because the participants are human, but because the incentive structure is sound.
Maybe we will have an Institute of Electrical and Electronics Agents papers at some point in the future.
And a conference for agents working at frontier?
This all makes me think of this episode from Rick & Morty.