ChatGPT and The Future of AI in Finance

I took the stage at the Cornell Quant Conference alongside Yu Yu (BlackRock) Tony Berkman (Two Sigma), and Samson Qian (Citadel), to discuss ChatGPT & The Future of AI in Finance.
Last week, I participated in a panel at the Cornell Financial Engineering Manhattan Conference. The topic of the panel was 'ChatGPT & The Future of AI in Finance.'
The other panelists were:
- Yu Yu, Director of Data Science - BlackRock
- Tony Berkman, Managing Director - Two Sigma
- Samson Qian, Trader - Citadel
After the discussion, several people reached out, mentioning it was one of their favorite panels of the day.
Since this wasn't recorded, I took the opportunity to write down some of the topics discussed, along with a few additional thoughts that I believe in.
I will organize the following sections based on the topics discussed at the event:
- Hallucinations
- Agents are the future
- When does it make sense to fine-tune?
- Compliance and Data security
1. Hallucinations
When talking about the topic of hallucinations, I have a quote that I love from Marc Andreesen:
"Hallucination is what we call when we don't like it. Creativity is what we call it when we do like it."
Confident hallucinations
The fundamental issue with hallucinations is the fact that the model hallucinates with confidence.
Imagine asking two different friends: "Do you know where location X is?"
Friend A: It's there.
Friend B: Hmm, I'm not really sure. If I had to guess, I'd say there, but I'm not 100% certain.
If both gave wrong directions, you would consider Friend A a liar, but not Friend B. This is because Friend B lacked confidence in their answer, they were trying to help but highlighted that they weren't sure about it.
The problem with current LLMs is that they are, for the most part, like Friend A. They say wrong things with certainty.
Hallucinations would be less problematic if the default behavior were more like the answer on the right, when the LLM is not 100% confident.
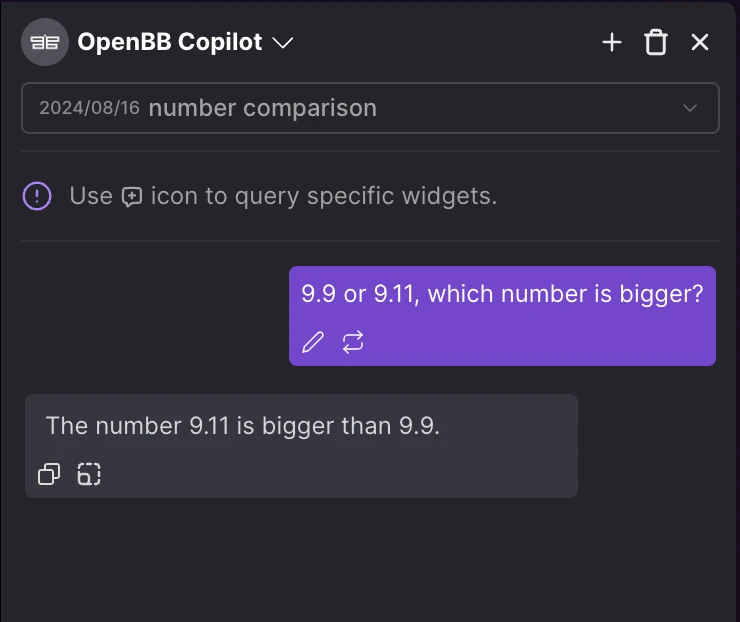
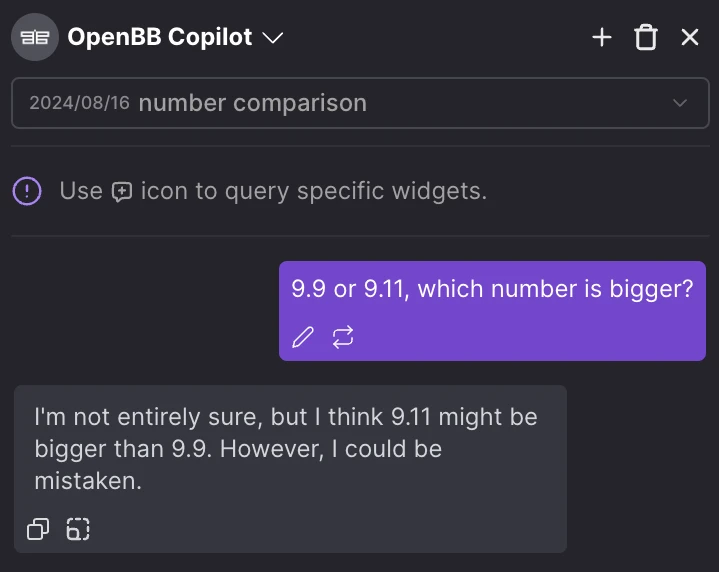
The problem with confident hallucinations is that, similar to why everyone dislikes liars, it leads to a lack of trust. So users begin to put everything that is output by an LLM under a microscope - even if what the model says is accurate.
How to avoid hallucinations
There are ways to address this and one of the key approaches we are extremely strong about at OpenBB is always tapping into information that is available.
When a user asks a question that requires financial data, the OpenBB Copilot always searches for that data on OpenBB (either through data we make available or through private data that customers bring).
The Copilot will only answer the question if that data exists. This allows the model to cite the data used in its response, so the user can double-check.
This is how it looks.
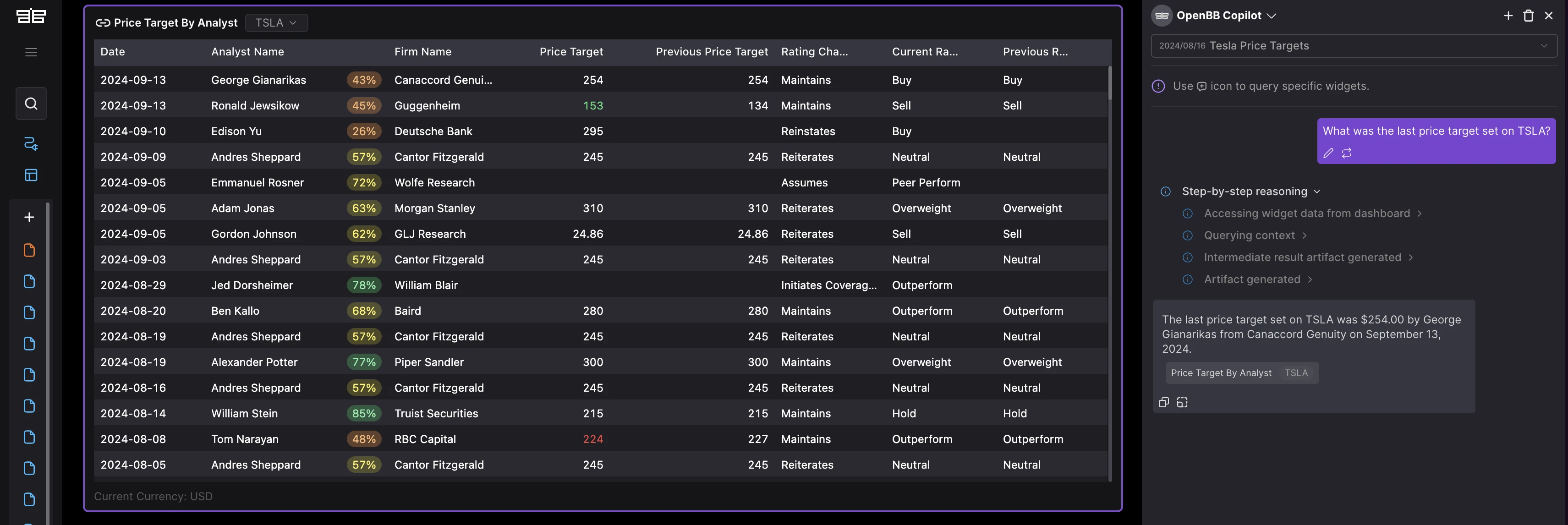
While I've heard a few vendors promising 100% accuracy, this is simply not true.
We are at a stage where technology is not even yet at the 'trust but verify' level.
So instead of hallucinating with confidence, when data is unavailable, we prompt the model to return that there was no real-time information accessible to answer the query.
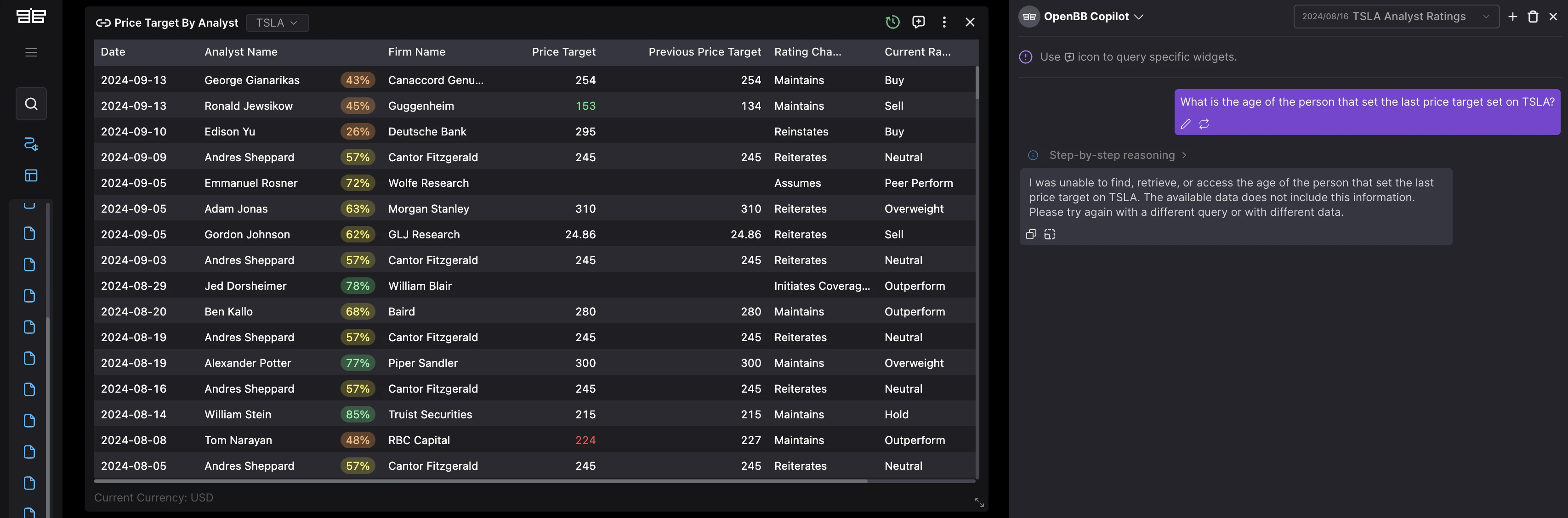
Function calling to increase accuracy
One thing we found that significantly reduces hallucinations is enabling our agent, OpenBB Copilot, to have access to all the API backends that users have through OpenBB or those they've added themselves.
Here's the sequence of actions that happen:
- The user asks the OpenBB Copilot a question.
- The prompt is converted into embeddings.
- We compare that embedding with all the ones that we have on an OpenBB vector store which contains widget signatures - name, description, category, subcategory and source.
- We retrieve the widgets with the highest similarity.
- The Copilot then decides which widget to use based on the prompt.
- Then Copilot also decides what parameters to use when calling that API
This leads to less hallucination because the LLM isn't outputting tokens based on a prompt and its internal weights. Instead, it's using its internal weights, the prompt, and a function call.
Assuming the function call succeeds - with correct widget retrieval and parameters - the data becomes available for the Copilot to use, which leads to higher accuracy.
Note: This still means that Copilot needs to use the correct widget and the correct parameter, but there's a higher likelihood of success because if it isn't, the API call will fail, prompting the LLM to try again.
Here's how it works behind the scenes, the OpenBB Copilot highlights its step-by-step reasoning so users can understand its thought process. Transparency is key.
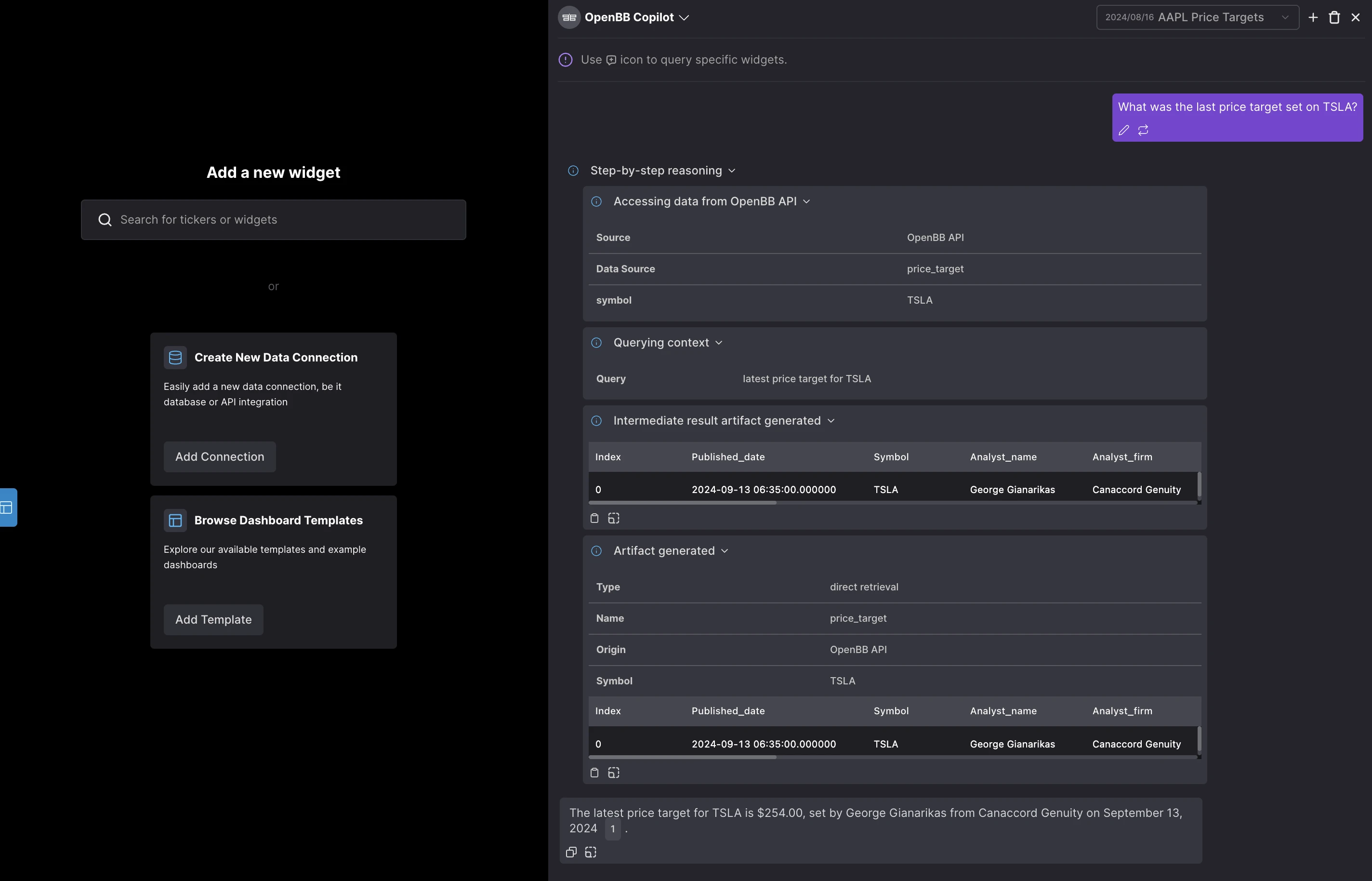
Workflows to avoid hallucinations
In order to reduce the number of hallucinations, there are two things that can be done.
Enable users to quickly detect whether a hallucination has occurred
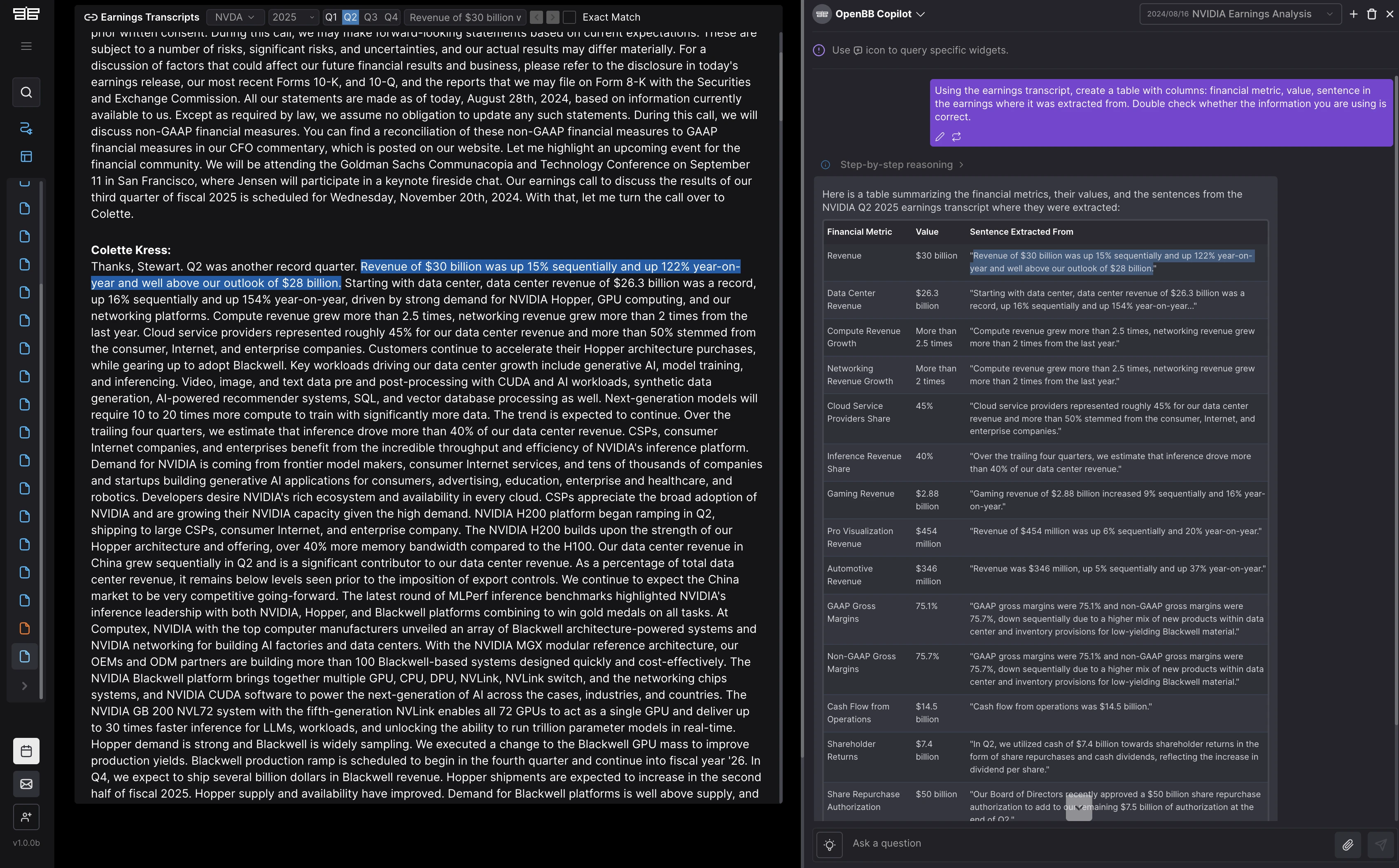
For instance, if a user utilizes the following prompt on the OpenBB Copilot:
Using the earnings transcript, create a table with columns: financial metric, value, sentence in the earnings where it was extracted from. Double check whether the information you are using is correct.
They get the "Sentence Extracted From" column, which they can copy and paste into a search field added at the top of the Earnings Transcript widget. This enable users to quickly validate the numbers that have been found.
See example below,
Add deterministic processes to check for hallucinations
For example, let's say the user prompt involves a data retrieval task.
We can run a deterministic process to check whether the retrieved values exist or not. Sure this won't be 100% accurate because the numbers could be flagged by referring to another thing, BUT it's all about improving the overall accuracy of Copilot.
Ultimately, whatever can be done to improve the Copilot's accuracy should be done.
2. Agents are the future
When we think about how humans operate, we recognize that the brain coordinates all the actions of our body and our thought processes. This is similar to how agents work.
If I'm playing soccer, the muscles I use are different from those I would use if I were boxing. If I'm programming, the parts of my brain I use differ from those I would use when listening to music.
However, it's not as simple as "activity A requires legs". Most of your body and mind are always involved, but at different times and in different capacities. And what dictates that are external factors.
For instance, if I am playing soccer as a winger and my team is attacking, I will likely be using both legs to run forward and a lot of mental energy to decide where to position myself on the field.
And that will change a lot based on where the ball is. If the ball is on the opposite side, I'll likely run less and stay more in the middle to be ready for a counterattack. If the ball is in the middle, I'll probably be running at full speed to create space. If the ball is close to me I have to worry more about controlling it and understand what I can do with it next.
The environment affects my plan to carry out an action where I want to have a successful outcome.
This is how agents work.
Agents aren't just about a single LLM performing well, but about a full workflow that interacts with multiple language models, function calls, or any other process to carry an action.
At the core, the biggest advantage of an agent over a LLM is that an agent has a full feedback loop. It understands the impact of the LLM output and can use that data in the next step of the process. Whereas a single LLM API call returns its best output but won't know how that affected the external environment.
This is why, at OpenBB, we believe in compound AI systems.
And apparently, so does Sequoia.
The "Strawberry" issue will be solved
A panelist commented on stage that LLMs can't even count how many R's are in the word "Strawberry".
This tweet offers a good explanation of why this happens — it turns out it's due to the tokenizer, and it can be solved. In fact, it's solved by simply ensuring that the model takes each letter as a token. See below,
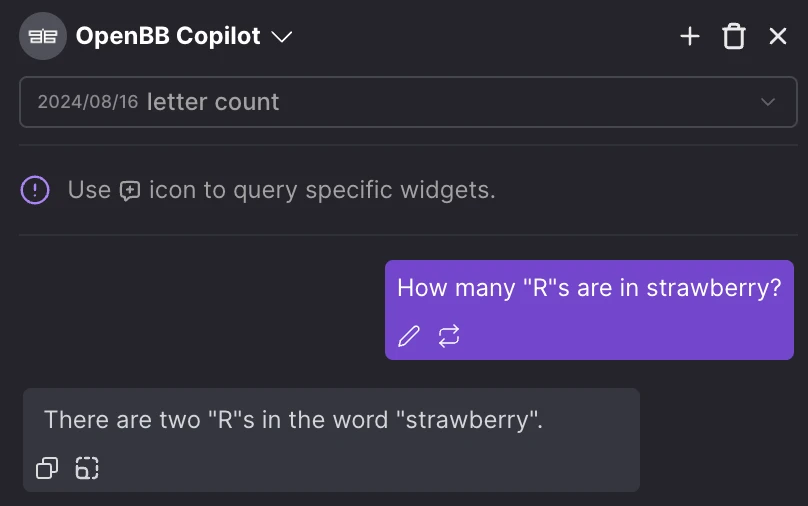
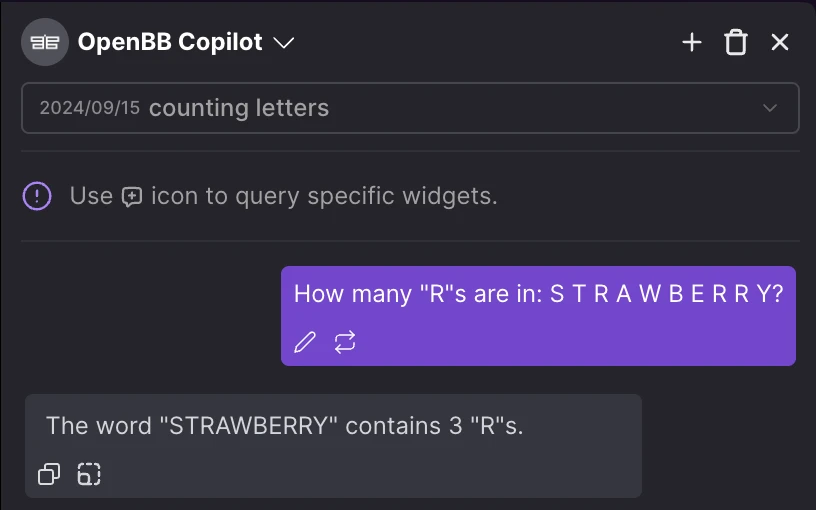
This means that the model's output can be improved by doing extra work at the input level.
Data cleaning and pre-processing strikes again? 😃
Interestingly, a few days ago, OpenAI announced OpenAI o1. Which is basically GPT-4o with Chain-of-Thought (COT). This means that this model is a "wannabe agent".
It takes in a prompt from the user and decomposes it in natural steps to solve it. Then at each step, it takes the output of the model from the previous step and predicts the next token. It turns out that this improves accuracy substantially.
However, it still doesn't have access to external data. And that is why I call it a "wannabe agent".
I love how Jeremiah put it in this tweet:
(...) Agents are also characterized by iterative behavior. But there's a key difference: while models like o1 iterate internally to refine their reasoning, agents engage in iterative interactions with the external world. They perceive the environment, take actions, observe the outcomes (or side effects) and adjust accordingly. This recursive process enables agents to handle tasks that require adaptability and responsiveness to real-world changes. (...)
So, o1's model isn't an agent - but it can solve this problem. The reason is that it applies its own data cleaning/pre-processing step on its own, and doesn't rely on external factors.
Small Language Models
Once agents work, Small Language Models (SLM) will be much more viable for very specific use cases.
In logical terms, a Large Language Model is a model with weights.
Large means that it has a lot of them. But what tends to happen is LLMs need to be very big because they want these models to be really good at everything. The problem is that if you want the exact same model to be good at discussing soccer, programming, and speaking Portuguese, its weights are updated using these drastically different datasets. Now the premise is that the more weights there are, the less each weight will be affected by data from completely different domains.
What a big LLM like GPT-4o is doing is trying to build a single Jarvis that knows about everything. Whereas we could have an SLM that does something extremely well and just focus on that, e.g. translating from English to Portuguese. The benefit of an SLM is that inference is likely faster, can be hosted on devices, and, in theory, it's better on a topic because it's been less "contaminated" during training by data that doesn't relate to the task at hand.
Imagine that a firm decides to use an SLM trained to retrieve data from SEC filings quickly and at scale. Or, we could train our own SLM to understand user intent and interact directly with the OpenBB Terminal interface.
Large Language Models as orchestrator
In my opinion, the best LLM in each category will win. And the second and third won't matter. It's a winner-takes-all kind of market. Unless in specific verticals such as inference time or open weights (e.g. for data security; more on this later).
The best example of this is OpenAI vs Anthropic.
I had been using OpenAI's GPT-4 for coding for several months. After trying Anthropic's Sonnet 3.5 for coding, I never went back to OpenAI.

The market share for the best LLM will be gigantic. That's why OpenAI is looking to raise at a $150 billion valuation. While the valuation reflects the market size, the amount that will be raised represents the capital needed to reach that valuation. This is why only a few players will be able to compete at that level.
In an "agentic future", I believe the best LLM will serve as the core "brain" - the main LLM that routes all prompts and decides what happens next.
And who wouldn't want the smartest model controlling the actions with a list of models, functions and data at its disposal?
I know I would.
That's also why, when discussing OpenBB Copilot, we don't rely on a single foundational model. Instead, we use the models that are best suited for each specific task.
For instance, OpenAI o1 can be the brains, but when a user uses @web it triggers the Perplexity model, and when they upload an image, we have Anthropic's Haiku. Or maybe if they want to do intraday trading, we use Llama 3.1 through Groq for fast inference.
You get the idea.
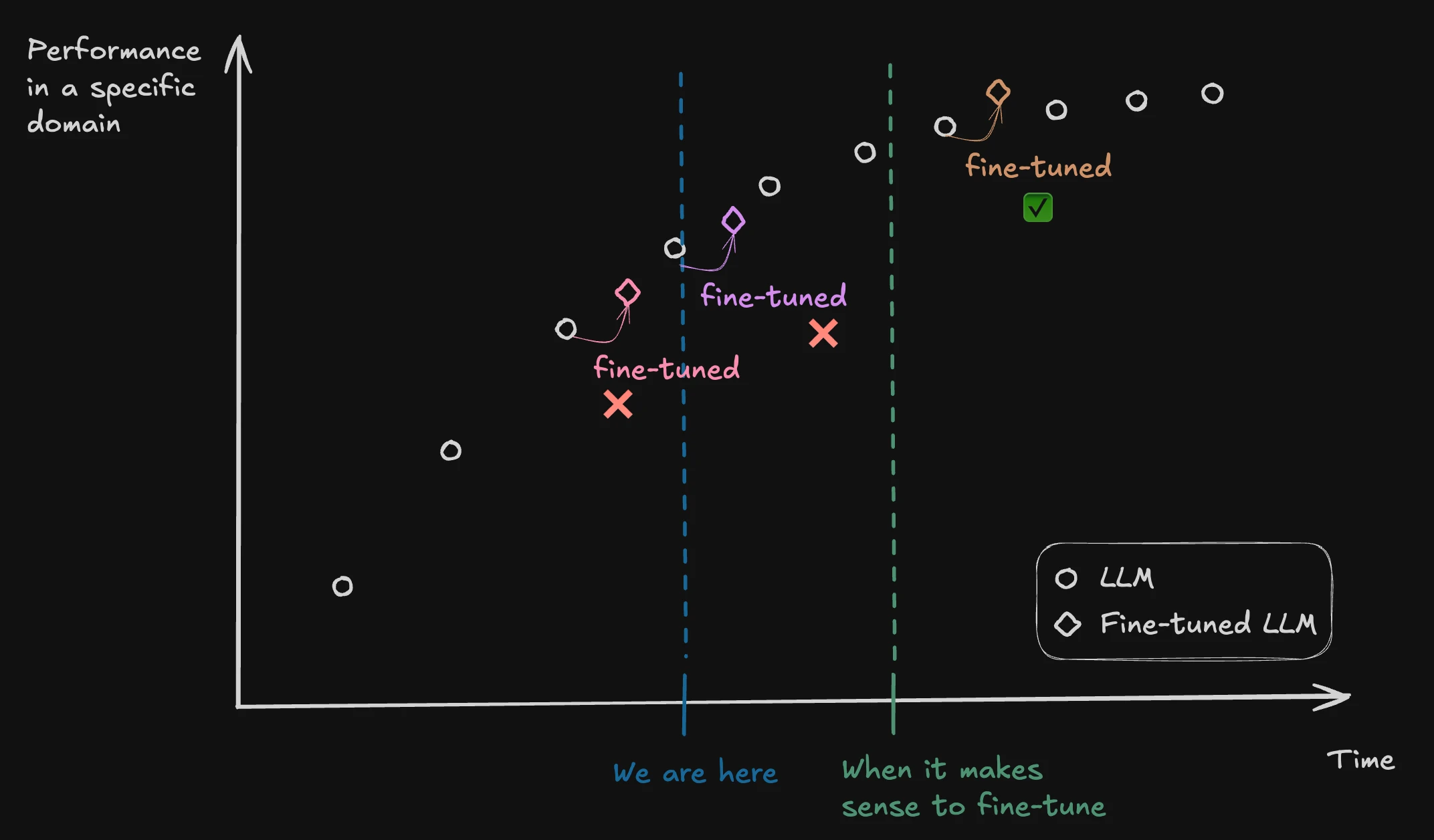
3. When does it make sense to fine-tune
A good comment was made on the panel: "it's expensive to spend time fine-tuning a new model, just for that entire work to be 'eradicated' by a new model that has a higher performance in that specific domain than the model has been fine-tuned".
In my opinion, this happens because the timing isn't right yet. We are still unlocking remarkable achievements through each new model release. Although there is a massive bump in terms of capability between these releases, I wouldn't recommend that a firm fine-tune its own models at this stage.
However, at some point, whether due to a lack of data to train or architecture needing to be reinvented, improvements in LLM performance won't be substantial - they may not even be noticeable. This is when the fine-tuning technique becomes relevant because at this stage you are trying to repurpose everything the model has towards a specific vertical / use-case - and at that vertical/use-case that model will be better than the following one.
Then after some new models come out, you may consider reapplying fine-tuning to that model, but this would likely be years later, not weeks or months. So, the ROI can be quite high. Particularly when you are trying to win in your specific market.
This is how I see it working in my head:
4. Compliance and Data security
Another question I received was about compliance and data security.
Recently, during a discussion with one of the largest hedge funds in the world, we were asked about the entire workflow of the data when our AI Copilot has access to it.
Their main concern was ensuring that no data was being shared with third-party vendors like OpenAI. For such firms, their data is their alpha, and keeping it within their network is paramount.
Crypto enthusiasts often say, "Not your keys, not your coins" to emphasize the importance of storing assets in a cold wallet rather than leaving them on an exchange that might implode (looking at you, FTX). The same principle applies here: "Not your weights, not your data".
When you send information to a large foundation model provider like OpenAI, your data enters their ecosystem, and you have to trust they'll honor the terms of your contract.
A more secure approach is to host an open-source model locally within your firm, ensuring that sensitive data remains entirely within your infrastructure and network.
Although open-source models aren't yet as powerful as closed-source ones, they are catching up quickly. If you think that GPT-4o can already do a lot for you, think about how at some point there will be an open-source model that is GPT-4o equivalent. Sure, at that time closed-source models will be better, but the question is: How much better?
Or better, the question is: "How much are you willing to sacrifice in terms of data security for performance?".
At OpenBB, we take this very seriously and have taken measures to allow enterprise customers to fully control their data.
Bring your own copilot
Enable firms to bring their own LLMs to access data within OpenBB. This means that we provide an interface for research, but also allow them to integrate their internal LLMs and interact directly with it from OpenBB.
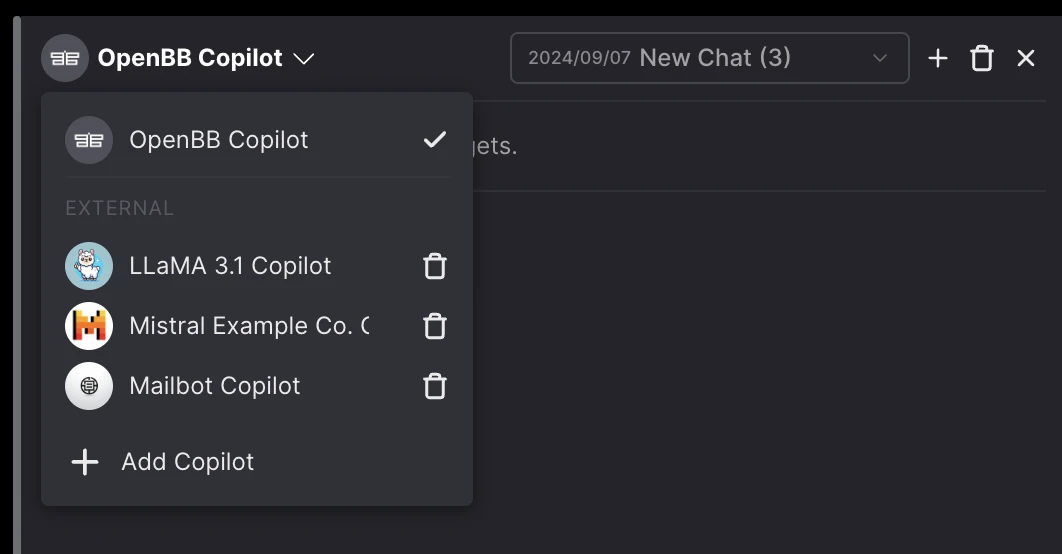
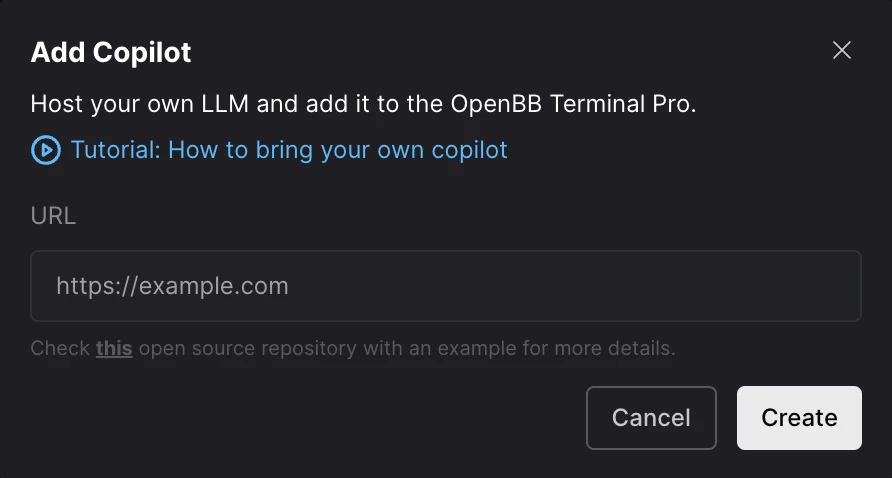
We believe in this idea so much, that we have open-source the architecture for firms to bring their own Copilot to OpenBB. More information is available here.
Turn off AI workflows
We have incorporated workflows that make users' lives MUCH better. But they come at a cost: sharing data with an LLM provider.
These are the features:
- Widget title/description suggestion from Copilot: This sends the content of the table or note output by Copilot to an LLM provider to receive suggestions of a title and description.
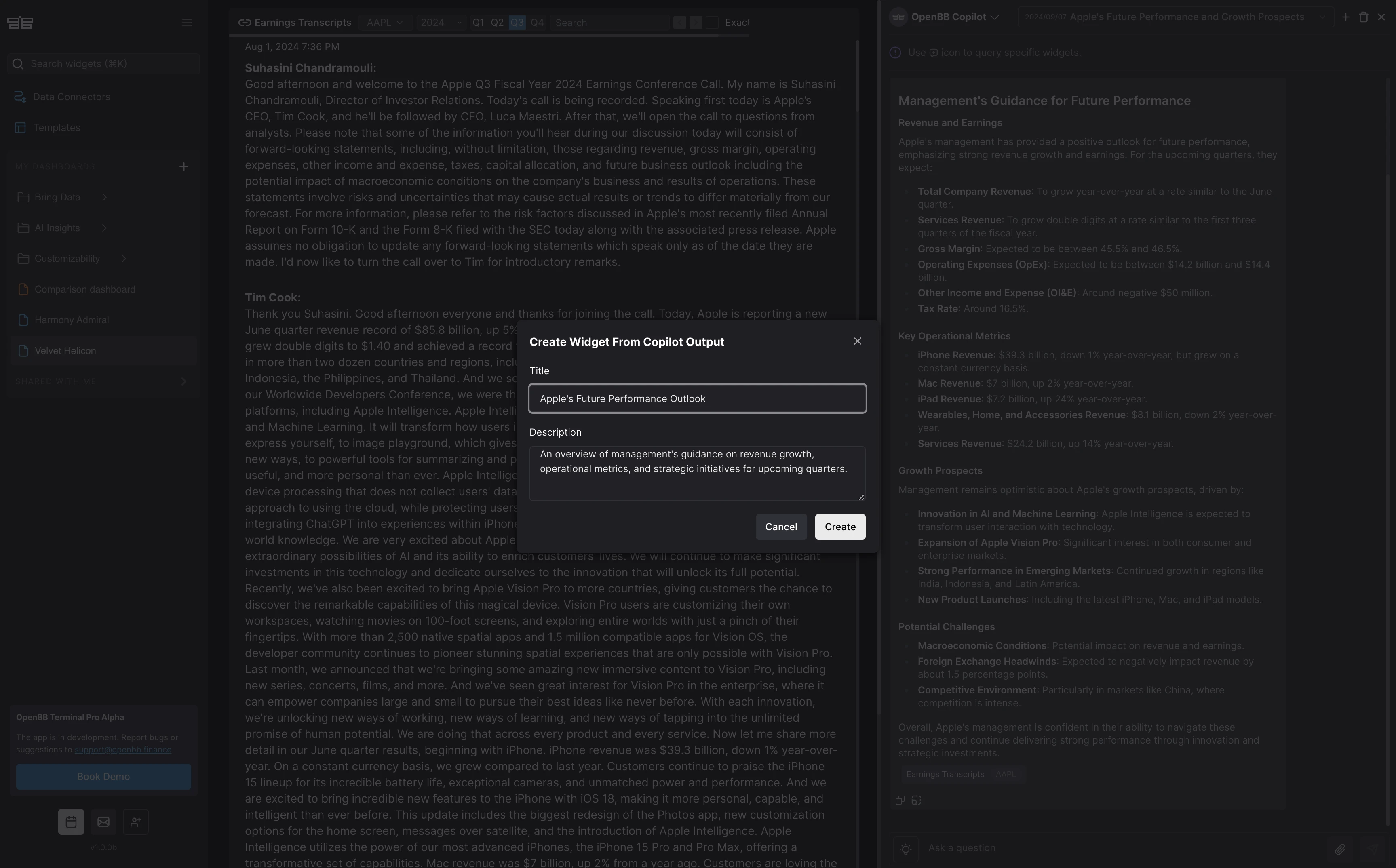
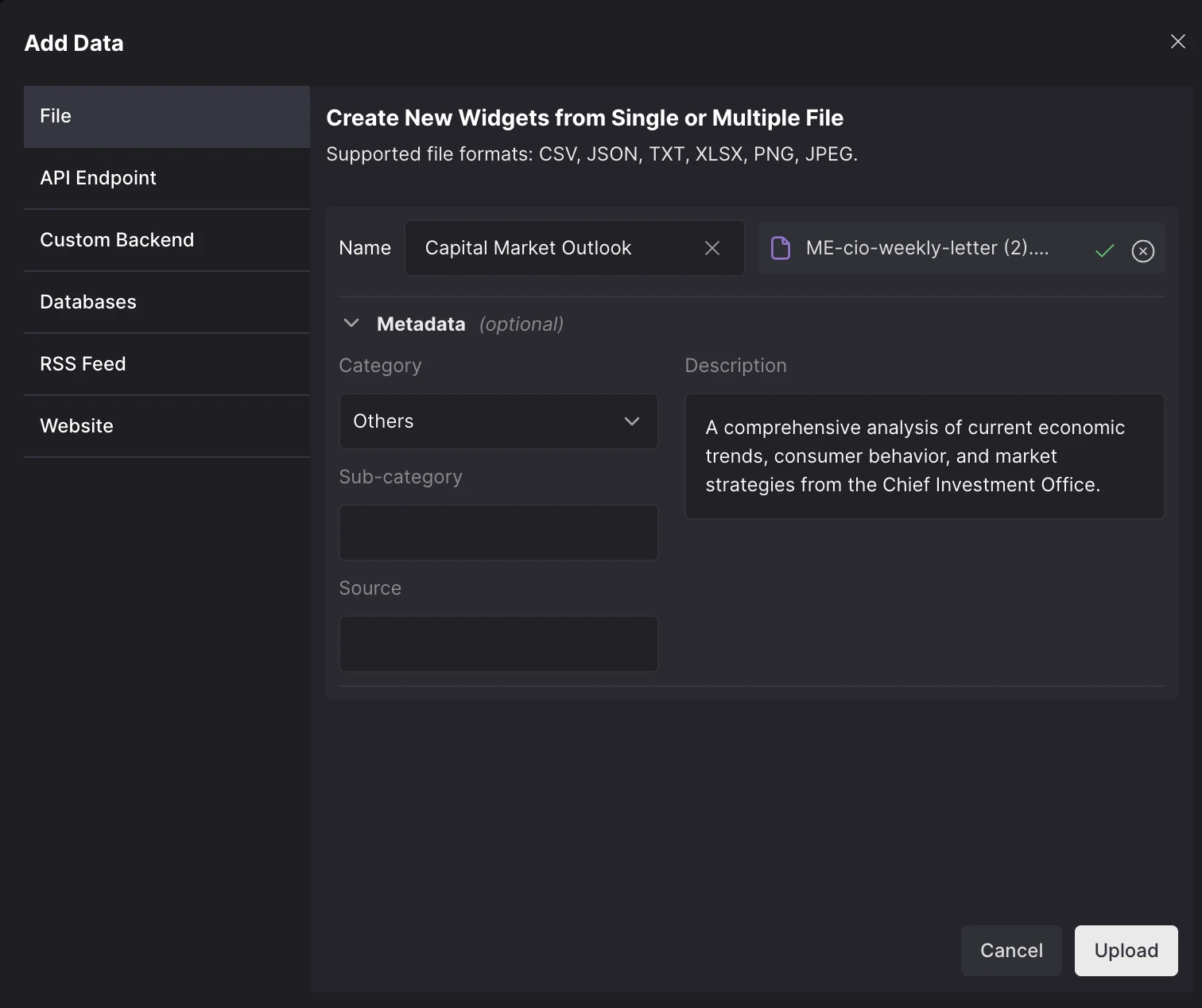
- Widget title/description suggestion upon upload: It sends the content of the file that has been uploaded to an LLM provider to receive suggestions of title and description.
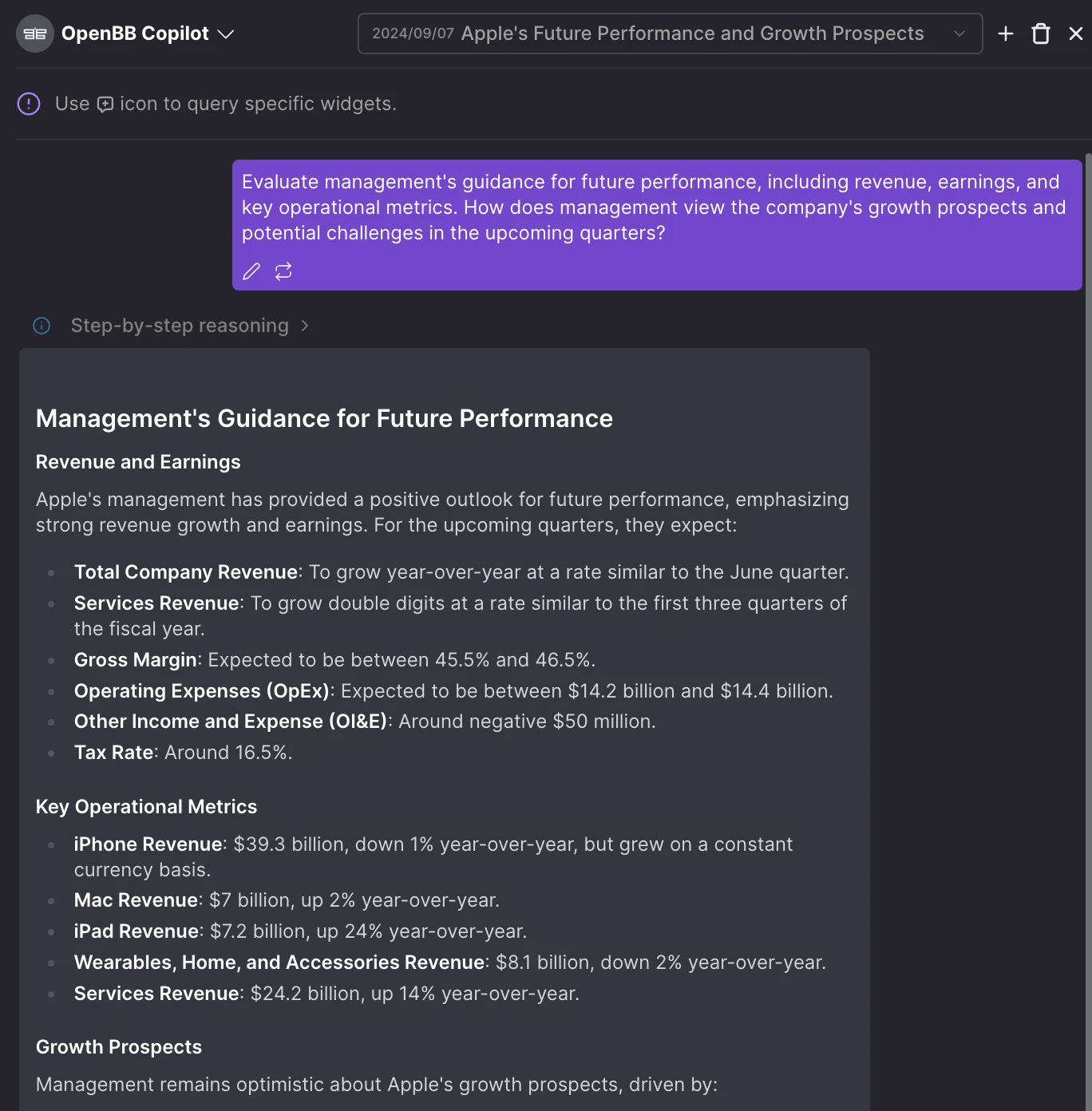
- Copilot chat title generation: Upon the first user prompt, the content is sent to an LLM provider to update the chat title, reflecting the nature of the conversation.
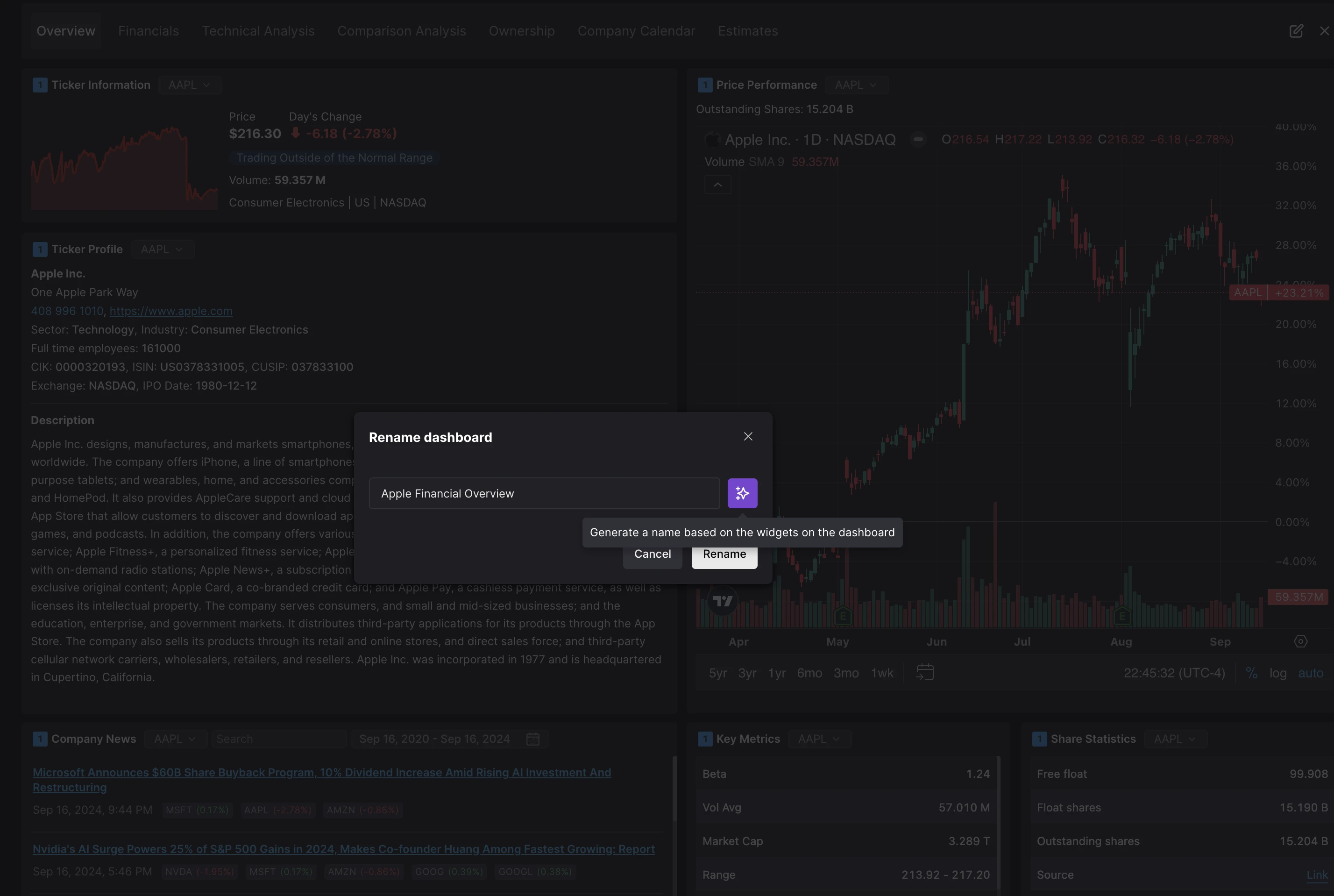
- Dashboard name generation: When renaming the dashboard, we send the title and descriptions of all widgets on that dashboard to an LLM provider, to ensure that the suggested name is relevant.
To allow firms to keep their data within their network, one of our enterprise features is the option to disable these AI workflows.

In the future, we could direct these AI workflows to use an LLM that our customers are running locally.
So, in a nutshell, what can you expect from OpenBB?
We are building an AI-powered research workspace.
At the core it is an AI compound system, where users can bring their own data (structured, unstructured, API, custom backend, database, data warehouse, etc..) and have our (or their own copilot) access all this data seamlessly - in an interface that is customizable, flexible and enables teams to work together.
If you want to learn more, e-mail me directly at didier.lopes@openbb.finance